Python in Machine Learning
Python in Machine Learning
PYTHON LANGUAGE
Import libraries
A module is a file containing definitions ; definitions from a module can be imported into other modules or into the main module.
You can touch a module’s global variables with the same notation used to refer to its functions, modname.itemname.
import modname
from modname import itemname
# 'generic import' of math module
import math
math.sqrt(25)
# import a function
from math import sqrt
sqrt(25)
# no longer have to reference the module
# import multiple functions at once
from math import cos, floor
# import all functions in a module (generally discouraged)
# from os import *
# define an alias
import numpy as np
# show all functions in math module
content = dir(math)
Packages
Packages are a way of structuring Python’s module namespace by using “dotted module names”. For example, the module name A.B designates a submodule named B in a package named A.
When importing the package, Python searches through the directories on sys.path looking for the package subdirectory.
The import statement uses the following convention: if a package’s __init__.py code defines a list named __all__, it is taken to be the list of module names that should be imported when from package import * is encountered.
__init__.py
The __init__.py files are required to make Python treat the directories as containing packages.
__init__.py can just be an empty file, but it can also execute initialization code for the package or set the __all__ variable.
If a package’s __init__.py code defines a list named __all__, it is taken to be the list of module names that should be imported when from package import * is encountered.
If __all__ is not defined, the statement from package import * does not import all submodules from the package.
distutils
The distutils package provides support for building and installing additional modules into a Python installation.Most Python users will not want to use this module directly, but instead use the cross-version tools maintained by the Python Packaging Authority pip. In particular, setuptools is an enhanced alternative to distutils that provides:
- support for declaring project dependencies
- additional mechanisms for configuring which files to include in source releases (including plugins for integration with version control systems)
- the ability to declare project “entry points”, which can be used as the basis for application plugin systems
- the ability to automatically generate Windows command line executables at installation time rather than needing to prebuild them
- consistent behaviour across all supported Python versions
How To Package Your Python Code
For ex., to create a module called funniest. The initial directory structure for funniest should look like this:
funniest/
funniest/
__init__.py
setup.py
from setuptools import setup
setup(name='funniest',
version='0.1',
description='The funniest joke in the world',
url='http://github.com/storborg/funniest',
author='Flying Circus',
author_email='flyingcircus@example.com',
license='MIT',
packages=['funniest'],
zip_safe=False)
$ pip install .
$ pip install -e .
Data types
# determine the type of an object
type(2)
# returns 'int'
type(2.0)
# returns 'float'
type('two')
# returns 'str'
type(True)
# returns 'bool'
type(None)
# returns 'NoneType'
# check if an object is of a given type
isinstance(2.0, int)
# returns False
isinstance(2.0, (int, float))
# returns True
# convert an object to a given type
float(2)
int(2.9)
str(2.9)
# zero, None, and empty containers are converted to False
bool(0)
bool(None)
bool('') # empty string
bool([]) # empty list
bool({}) # empty dictionary
# non-empty containers and non-zeros are converted to True
bool(2)
bool('two')
bool([2])
Math
# basic operations
10 + 4 # add (returns 14)
10 - 4 # subtract (returns 6)
10 * 4 # multiply (returns 40)
10 ** 4 # exponent (returns 10000)
10 / 4 # divide (returns 2 because both types are 'int')
10 / float(4) # divide (returns 2.5)
5 % 4 # modulo (returns 1) - also known as the remainder
10 / 4 # true division (returns 2.5)
10 // 4 # floor division (returns 2)
Comparisons and boolean operations
# comparisons (these return True)
5 > 3
5 >= 3
5 != 3
5 == 5
# boolean operations (these return True)
5 > 3 and 6 > 3
5 > 3 or 5 < 3
not False
False or not False and True # evaluation order: not, and, or
Conditional statements
x = 3
# if statement
if x > 0:
print('positive')
# if/else statement
if x > 0:
print('positive')
else:
print('zero or negative')
# if/elif/else statement
if x > 0:
print('positive')
elif x == 0:
print('zero')
else:
print('negative')
Lists
Different objects categorized along a certain ordered sequence, lists are ordered, iterable, mutable (adding or removing objects changes the list size), can contain multiple data types.
# create an empty list (two ways)
empty_list = []
empty_list = list()
# create a list
simpsons = ['homer', 'marge', 'bart']
# examine a list
simpsons[0]
# print element 0 ('homer')
len(simpsons)
# returns the length (3)
# modify a list (does not return the list)
simpsons.append('lisa')# append element to end
simpsons.extend(['itchy', 'scratchy']) # append multiple elements to end
simpsons.insert(0, 'maggie') # insert element at index 0 (shifts everything right)
simpsons.remove('bart') # searches for first instance and removes it
simpsons.pop(0) # removes element 0 and returns it
del simpsons[0] # removes element 0 (does not return it)
simpsons[0] = 'krusty' # replace element 0
# concatenate lists (slower than 'extend' method)
neighbors = simpsons + ['ned','rod','todd']
# find elements in a list
simpsons.count('lisa') # counts the number of instances
simpsons.index('itchy') # returns index of first instance
# list slicing [start:end:stride]
weekdays = ['mon','tues','wed','thurs','fri']
weekdays[0] # element 0
weekdays[0:3] # elements 0, 1, 2
weekdays[:3] # elements 0, 1, 2
weekdays[3:] # elements 3, 4
weekdays[-1] # last element (element 4)
weekdays[::2] # every 2nd element (0, 2, 4)
weekdays[::-1] # backwards (4, 3, 2, 1, 0)
# alternative method for returning the list backwards
list(reversed(weekdays))
# sort a list in place (modifies but does not return the list)
simpsons.sort()
simpsons.sort(reverse=True) # sort in reverse
simpsons.sort(key=len) # sort by a key
# return a sorted list (but does not modify the original list)
sorted(simpsons)
sorted(simpsons, reverse=True)
sorted(simpsons, key=len)
# create a second reference to the same list
num = [1, 2, 3]
same_num = num
same_num[0] = 0 # modifies both 'num' and 'same_num'
# copy a list (three ways)
new_num = num.copy()
new_num = num[:]
new_num = list(num)
# examine objects
id(num) == id(same_num) # returns True
id(num) == id(new_num) # returns False
num is same_num # returns True
num is new_num # returns False
num == same_num # returns True
num == new_num # returns True (their contents are equivalent)
# conatenate +, replicate *
[1, 2, 3] + [4, 5, 6]
["a"] * 2 + ["b"] * 3
Tuples
A tuple is a sequence of immutable Python objects. Tuples are sequences, just like lists. The differences between tuples and lists are, the tuples cannot be changed unlike lists and tuples use parentheses, whereas lists use square brackets. Creating a tuple is as simple as putting different comma-separated values.
# create a tuple
digits = (0, 1, 'two') # create a tuple directly
digits = tuple([0, 1, 'two']) # create a tuple from a list
zero = (0,) # trailing comma is required to indicate it's a tuple
# examine a tuple
digits[2] # returns 'two'
len(digits) # returns 3
digits.count('two') # counts the number of instances of 'two'
digits.index('two') # returns the index of the first instance of 'two'
# elements of a tuple cannot be modified
# digits[2] = 2 # throws an error
# concatenate tuples
digits = digits + (3, 4)
# create a single tuple with elements repeated (also works with lists)
(3, 4) * 2 # returns (3, 4, 3, 4)
# tuple unpacking
bart = ('male', 10, 'simpson') # create a tuple
Strings
A sequence of characters, they are iterable, immutable.
# create a string
s = str(42) # convert another data type into a string
s = 'I like you'
# examine a string
s[0] # returns 'I'
len(s) # returns 10
# string slicing like lists
s[:6] # returns 'I like'
s[7:] # returns 'you'
s[-1] # returns 'u'
# basic string methods (does not modify the original string)
s.lower() # returns 'i like you'
s.upper() # returns 'I LIKE YOU'
s.startswith('I') # returns True
s.endswith('you') # returns True
s.isdigit() # returns False (returns True if every character in the string is a digit)
s.find('like') # returns index of first occurrence (2), but doesn't support regex
s.find('hate') # returns -1 since not found
s.replace('like','love') # replaces all instances of 'like' with 'love'
# split a string into a list of substrings separated by a delimiter
s.split(' ') # returns ['I','like','you']
s.split() # same thing
s2 = 'a, an, the'
s2.split(',') # returns ['a',' an',' the']
# join a list of strings into one string using a delimiter
stooges = ['larry','curly','moe']
' '.join(stooges) # returns 'larry curly moe'
# concatenate strings
s3 = 'The meaning of life is'
s4 = '42'
s3 + ' ' + s4 # returns 'The meaning of life is 42'
s3+''+str(42) # same thing
# remove whitespace from start and end of a string
s5=' hamandcheese '
s5.strip() # returns 'ham and cheese'
# string substitutions: all of these return 'raining cats and dogs'
'raining %s and %s' % ('cats','dogs') # old way
'raining {} and {}'.format('cats','dogs') # new way
'raining {arg1} and {arg2}'.format(arg1='cats',arg2='dogs') # named arguments
# string formatting
# more examples: http://mkaz.com/2012/10/10/python-string-format/
'pi is {:.2f}'.format(3.14159) # returns 'pi is 3.14'
# normal strings versus raw strings
print('first line\nsecond line') # normal strings allow for escaped characters
print(r'first line\nfirst line') # raw strings treat backslashes as literal characters
Dictionaries
Dictionaries are structures which can contain multiple data types, and is ordered with key-value pairs: for each (unique) key, the dictionary outputs one value. Keys can be strings, numbers, or tuples, while the corresponding values can be any Python object. Dictionaries are: unordered, iterable, mutable.
# create an empty dictionary (two ways)
empty_dict = {}
empty_dict = dict()
# create a dictionary (two ways)
family = {'dad':'homer', 'mom':'marge', 'size':6}
family = dict(dad='homer', mom='marge', size=6)
# convert a list of tuples into a dictionary
list_of_tuples = [('dad','homer'), ('mom','marge'), ('size', 6)]
family = dict(list_of_tuples)
# examine a dictionary
family['dad'] # returns 'homer'
len(family) # returns 3
family.keys() # returns list: ['dad', 'mom', 'size']
family.values()# returns list: ['homer', 'marge', 6]
family.items() # returns list of tuples: [('dad', 'homer'), ('mom', 'marge'), ('size', 6)]
'mom' in family # returns True
'marge' in family # returns False (only checks keys)
# modify a dictionary (does not return the dictionary)
family['cat'] = 'snowball' # add a new entry
family['cat'] = 'snowball ii' # edit an existing entry
del family['cat'] # delete an entry
family['kids'] = ['bart', 'lisa'] # value can be a list
family.pop('dad') # removes an entry and returns the value ('homer')
family.update({'baby':'maggie', 'grandpa':'abe'}) # add multiple entries # accessing values more safely with 'get'
# accessing values more safely with 'get'
family['mom'] # returns 'marge'
family.get('mom') # same thing
try:
family['grandma']
except KeyError as e:
print("Key Error:", e) # Key Error: 'son'
family.get('grandma') # returns None
family.get('grandma', 'not found') # returns 'not found' (the default)
# accessing a list element within a dictionary
family['kids'][0] # returns 'bart'
family['kids'].remove('lisa') # removes 'lisa'
# string substitution using a dictionary
'youngest child is %(baby)s' % family # returns 'youngest child is maggie'
Sets
Like dictionaries, but with unique keys only (no corresponding values). They are: unordered, iterable, mutable, can contain multiple data types made up of unique elements (strings, numbers, or tuples)
# create an empty set
empty_set = set()
# create a set
languages = {'python', 'r', 'java'} # create a set directly
snakes = set(['cobra', 'viper', 'python']) # create a set from a list
# examine a set
len(languages) # returns 3
'python' in languages # returns True
# set operations
languages & snakes # returns intersection: {'python'}
languages | snakes # returns union: {'cobra', 'r', 'java', 'viper', 'python'}
languages - snakes # returns set difference: {'r', 'java'}
snakes - languages # returns set difference: {'cobra', 'viper'}
# modify a set (does not return the set)
languages.add('sql') # add a new element
languages.add('r') # try to add an existing element (ignored, no error)
languages.remove('java') # remove an element
try:
languages.remove('c') # try to remove a non-existing element (throws an error)
except KeyError as e:
print("Error", e)
languages.discard('c') # removes an element if presense
languages.pop() # removes and returns an arbitrary element
languages.clear() # removes all elements
languages.update('go', 'spark') # add multiple elements (can also pass a list or set)
# get a sorted list of unique elements from a list
sorted(set([9, 0, 2, 1, 0])) # returns [0, 1, 2, 9]
Functions
Functions are sets of instructions launched when called upon, they can have multiple input values and a return value
# define a function with no arguments and no return values
def print_text():
print('this is text')
# call the function
print_text()
# define a function with one argument and no return values
def print_this(x):
print(x)
# call the function
print_this(3) # prints 3
n = print_this(3)# prints 3, but doesn't assign 3 to n because the function has no return statement
# define a function with one argument and one return value
def square_this(x):
return x ** 2
# include an optional docstring to describe the effect of a function
def square_this(x):
"""Return the square of a number."""
return x ** 2
# call the function
square_this(3) # prints 9
var = square_this(3) # assigns 9 to var, but does not print 9
# default arguments
def power_this(x, power=2):
return x ** power
power_this(2) # 4
power_this(2, 3) # 8
# use 'pass' as a placeholder if you haven't written the function body
def stub():
pass
# return two values from a single function
def min_max(nums):
return min(nums), max(nums)
# return values can be assigned to a single variable as a tuple
nums = [1, 2, 3]
min_max_num = min_max(nums) # min_max_num = (1, 3)
# return values can be assigned into multiple variables using tuple unpacking
min_num, max_num = min_max(nums) # min_num = 1, max_num = 3
Loops
Loops are a set of instructions which repeat until termination conditions are met. This can include iterating through all values in an object, go through a range of values, etc.
# range returns a list of integers
range(0, 3) # returns [0, 1, 2]: includes first value but excludes second value
range(3) # same thing: starting at zero is the default
range(0, 5, 2) # returns [0, 2, 4]: third argument specifies the 'stride'
# for loop (not recommended)
fruits = ['apple', 'banana', 'cherry']
for i in range(len(fruits)):
print(fruits[i].upper())
# alternative for loop (recommended style)
for fruit in fruits:
print(fruit.upper())
# use range when iterating over a large sequence to avoid actually creating the integer list in memory
for i in range(10**6):
pass
# iterate through two things at once (using tuple unpacking)
family = {'dad':'homer', 'mom':'marge', 'size':6}
for key, value in family.items():
print(key, value)
# use enumerate if you need to access the index value within the loop
# enumerate allows us to loop over something and have an automatic counter.
my_list = ['apple', 'banana', 'grapes', 'pear']
for c, value in enumerate(my_list):
print(c, value)
# Output:
# 0 apple
# 1 banana
# 2 grapes
# 3 pear
# for/else loop
for fruit in fruits:
if fruit == 'banana':
print("Found the banana!")
break # exit the loop and skip the 'else' block
# this block executes ONLY if the for loop completes without hitting 'break'
else:
print("Can't find the banana")
# while loop
count = 0
while count < 5:
print("This will print 5 times")
count += 1 # equivalent to 'count = count + 1'
List comprehensions
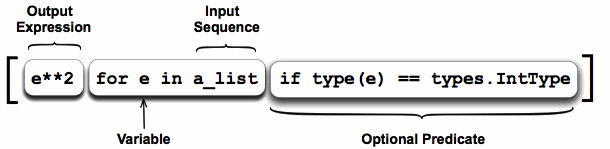
Comprehensions are constructs that allow sequences to be built from other sequences. Python 2.0 introduced list comprehensions and Python 3.0 comes with dictionary and set comprehensions. A list comprehension consists of the following parts:- An Input Sequence.
- A Variable representing members of the input sequence.
- An Optional Predicate expression.
- An Output Expression producing elements of the output list from members of the Input Sequence that satisfy the predicate.
a_list = [1, ‘4’, 9, ‘a’, 0, 4]
squared_ints = [ e**2 for e in a_list if type(e) == types.IntType ]
print squared_ints
# [ 1, 81, 0, 16 ]
# for loop to create a list of cubes
nums = [1, 2, 3, 4, 5]
cubes = []
for num in nums:
cubes.append(num**3)
# equivalent list comprehension
cubes = [num**3 for num in nums]
# [1, 8, 27, 64, 125]
# for loop to create a list of cubes of even numbers
cubes_of_even = []
for num in nums:
if num % 2 == 0:
cubes_of_even.append(num**3)
# equivalent list comprehension
# syntax: [expression for variable in iterable if condition]
cubes_of_even = [num**3 for num in nums if num % 2 == 0] # [8, 64]
# for loop to cube even numbers and square odd numbers
cubes_and_squares = []
for num in nums:
if num % 2 == 0:
cubes_and_squares.append(num**3)
else:
cubes_and_squares.append(num**2)
# equivalent list comprehension (using a ternary expression)
# syntax: [true_condition if condition else false_condition for variable in iterable]
cubes_and_squares = [num**3 if num % 2 == 0 else num**2 for num in nums] # [9, 64, 25]
# for loop to flatten a 2d-matrix
matrix = [[1, 2], [3, 4]]
items = []
for row in matrix:
for item in row:
items.append(item)
# equivalent list comprehension
items = [item for row in matrix for item in row] # [1 2 3 4]
# set comprehension
fruits = ['apple', 'banana', 'cherry']
unique_lengths = {len(fruit) for fruit in fruits} # {5, 6}
# dictionary comprehension
fruit_lengths = {fruit:len(fruit) for fruit in fruits} # {'apple': 5, banana': 6, 'cherry': 6}
Exceptions handling
dct = dict(a=[1, 2], b=[4, 5])
key = 'c'
try:
dct[key]
except:
print("Key %s is missing. Add it with empty value" % key)
dct['c'] = []
print(dct)
Basic operating system interfaces (os)
import os
import tempfile
tmpdir = tempfile.gettempdir()
# list containing the names of the entries in the directory given by path.
os.listdir(tmpdir)
# Change the current working directory to path.
os.chdir(tmpdir)
# Get current working directory.
print('Working dir:', os.getcwd()) # Join paths
mytmpdir = os.path.join(tmpdir, "foobar")
# Create a directory
if not os.path.exists(mytmpdir):
os.mkdir(mytmpdir)
filename = os.path.join(mytmpdir, "myfile.txt")
print(filename)
# Write
lines = ["Dans python tout est bon", "Enfin, presque"]
## write line by line
fd = open(filename, "w")
fd.write(lines[0] + "\n")
fd.write(lines[1]+ "\n")
fd.close()
## use a context manager to automatically close your file
with open(filename, 'w') as f:
for line in lines:
f.write(line + '\n')
# Read
## read one line at a time (entire file does not have to fit into memory)
f = open(filename, "r")
f.readline() # one string per line (including newlines)
f.readline() # next line
f.close()
## read one line at a time (entire file does not have to fit into memory)
f = open(filename, 'r')
f.readline() # one string per line (including newlines)
f.readline() # next line
f.close()
## read the whole file at once, return a list of lines
f = open(filename, 'r')
f.readlines() # one list, each line is one string
f.close()
## use list comprehension to duplicate readlines without reading entire file at once
f = open(filename, 'r')
[line for line in f]
f.close()
## use a context manager to automatically close your file
with open(filename, 'r') as f:
lines = [line for line in f]
Object Oriented Programing (OOP)
We can create a class which serves as a template for suitable objects by defining a list of methods that these objects must implement. n Python we can’t prevent anyone from instantiating a class, but we can create something similar to an abstract class by using NotImplementedError inside our method definitions. For example, here are some “abstract” classes which can be used as templates for shapes:
class Shape2D:
def area(self):
raise NotImplementedError()
class Shape3D:
def volume(self):
raise NotImplementedError()
import math
class Shape2D:
def area(self):
raise NotImplementedError()
# __init__ is a special method called the constructor
# Inheritance + Encapsulation
class Square(Shape2D):
def __init__(self, width):
self.width = width
def area(self):
return self.width ** 2
class Disk(Shape2D):
def __init__(self, radius):
self.radius = radius
def area(self):
return math.pi * self.radius ** 2
shapes = [Square(2), Disk(3)] # Polymorphism
print([s.area() for s in shapes])
s = Shape2D()
try:
s.area()
except NotImplementedError as e:
print("NotImplementedError")
References
- Statistics and Machine Learning in Python by Edouard Duchesnay, Tommy Löfstedt
Learning Python
5th Edition by Mark LutzCHAPTER 7 String Fundamentals
- Empty string
S = ''
S = "spam's"
S = 's\np\ta\x00m'
S = """...multiline..."""
S = r'\temp\spam'
B = b'sp\xc4m'
U = u'sp\u00c4m'
S1 + S2
S* 3
S[i]
S[i:j]
len(S)
"a %s parrot" % kind
"a {0} parrot".format(kind)
S.find('pa')
S.rstrip()
S.replace('pa', 'xx')
S.split(',')
S.isdigit()
S.lower()
S.endswith('spam')
'spam'.join(strlist)
S.encode('latin-1')
B.decode('utf8')
for x in S:
print(x)
'spam' in S
[c * 2 for c in S]
map(ord, S)
re.match('sp(.*)am', line)
CHAPTER 9 Tuples, Files, and Everything Else
Storing Native Python Objects: pickle
The pickle module is a more advanced tool that allows us to store almost any Python object in a file directly.
The pickle module performs what is known as object serialization — converting objects to and from strings of bytes.
As the dictionary object as an example:
>>> D = {'a': 1, 'b': 2}
>>> F = open('datafile.pkl', 'wb')
>>> import pickle
>>> pickle.dump(D, F) # Pickle any object to file
>>> F.close()
>>> F = open('datafile.pkl', 'rb')
>>> E = pickle.load(F) # Load any object from file
>>> E
{'a': 1, 'b': 2}
CHAPTER 11 Assignments, Expressions, and Prints
Print Operations
Printing is also one of the most visible places where Python 3.X and 2.X have diverged. In fact, this divergence is usually the first reason that most 2.X code won’t run un- changed under 3.X.- In Python 3.X, printing is a built-in function
print([object, ...][, sep=' '][, end='\n'][, file=sys.stdout][, flush=False])
- sep a string inserted between each object’s text, which defaults to a single space if not passed; passing an empty string suppresses separators altogether.
- end a string added at the end of the printed text, which defaults to a \n newline character if not passed.
- file specify file-like object to which the text will be sent; it defaults to the sys.stdout standard output stream if not passed.
- flush added in 3.3, defaults to False.
>>> x = 'spam'
>>> y = 99
>>> z = ['eggs']
>>> print(x, y, z)
spam 99 ['eggs']
>>> print(x, y, z, sep='') # Suppress separator
spam99['eggs']
>>> print(x, y, z, sep=', ') # Custom separator
spam, 99, ['eggs']
| 2.x | 3.x |
|---|---|
| print x, y | print(x, y) |
| print x, y, | print(x, y, end='') |
PART V Modules and Packages
CHAPTER 22 Modules: The Big Picture
Each file is a module, and modules import other modules to use the names they define. Why Use Modules? Modules is served as a namespace, modules are normally imported by other files that wish to use the tools the modules define. Variable names such as functions attached to object are called attributes. Cross-file module linking is not re- solved until such import statements are executed at runtime, objects defined by a module are also created at runtime, as the import is executing. The first time a program imports a given file:- Find the module’s file. Python uses a standard module search path and known file types to locate the module file corresponding to an import statement. sys.path is the module search path configured at program startup, automatically merging the home directory of the top-level file, any PYTHONPATH directories, the contents of any .pth file paths you’ve created, and all the standard library directories.
- Compile it to byte code (if needed). when you execute a program, Python first compiles your source code (the statements in your file) into a format known as byte code. It will store the byte code of your programs in files that end with a .pyc extension (“.pyc” means compiled “.py” source). During an import operation Python checks both file modification times and the byte code’s Python version number to decide how to proceed: both source code changes and differing Python version numbers will trigger a new byte code file.
- Run the module’s byte code to build the objects it defines. All statements in the file are run in turn, from top to bottom, and any assignments made to names during this step generate attributes of the resulting module object.
CHAPTER 23 Module Coding Basics
Modules are just namespaces (places where names are created), and the names that live in a module are called its attributes.- import module we must go through the module name to fetch its attributes
import module1 # Get module as a whole (one or more)
module1.printer('Hello world!')
from module1 import printer # Copy out a variable (one or more)
printer('Hello world!')
CHAPTER 24 Module Packages
A directory of Python code is said to be a package, a package import turns a directory on your computer into another Python name- space, with attributes corresponding to the subdirectories and module files that the directory contains. The directory paths in your import statements can be only variables separated by periods.
import dir1.dir2.mod
PART VI Classes and OOP
CHAPTER 26 OOP: The Big Picture
In Python, classes are created with a new statement: the class. Classes, though, are designed to create and manage new objects, and support inheritance. Notice that in the Python object model, classes and the instances you generate from them are two distinct object types:- Classes Serve as instance factories.
- Instances Represent the concrete items in a program’s domain.
CHAPTER 27 Class Coding Basics
Example,- The First Example
class FirstClass: # Define a class object
def setdata(self, value): # Define class's methods
self.data = value # self is the instance
def display(self):
print(self.data) # self.data: per instance
# Make two instances. Each is a new namespace
x = FirstClass()
y = FirstClass()
x.setdata("King Arthur") # Call methods: self is x
y.setdata(3.14159) # Runs: FirstClass.setdata(y, 3.14159)
x.display() # self.data differs in each instance King Arthur
y.display() # Runs: FirstClass.display(y) 3.14159
class SecondClass(FirstClass): # Inherits setdata
def display(self): # Changes display
print('Current value = "%s"' % self.data)
z = SecondClass()
z.setdata(42) # Finds setdata in FirstClass
z.display() # Finds overridden method in SecondClass
Current value = "42"
from modulename import FirstClass
class SecondClass(FirstClass):
def display(self): ...
import modulename
class SecondClass(modulename.FirstClass):
def display(self): ...
- Methods named with double underscores (__X__) are special hooks. The Python language defines a fixed and unchangeable mapping from each of these operations to a specially named method. For instance, an __add__ method is mapped to a + expression.
- Such methods are called automatically when instances appear in built-in operations.
- Classes may override most built-in type operations.
class C:
counter = 0
def __init__(self):
type(self).counter += 1
def __del__(self):
type(self).counter -= 1
if __name__ == "__main__":
x = C()
print("Number of instances: : " + str(C.counter))
y = C()
print("Number of instances: : " + str(C.counter))
del x
print("Number of instances: : " + str(C.counter))
del y
print("Number of instances: : " + str(C.counter))
class rec: pass # Empty namespace object
rec.name = 'Bob' # Just objects with attributes
rec.age = 40
x = rec() # Instances inherit class names
y = rec()
x.name, y.name # name is stored on the class only
('Bob', 'Bob')
x.name = 'Sue' # But assignment changes x only
rec.name, x.name, y.name
('Bob', 'Sue', 'Bob')
list( rec.__dict__.keys() )
list(name for name in rec.__dict__ if not name.startswith('__'))
>>> x.age # attribute fetch checks classes
40
>>> x.__dict__['age'] # Indexing dict does not do inheritance search
KeyError: 'age'
x.__class__ # Instance to class link
rec.__bases__ # Class to superclasses link
# defines a simple function outside of any class
def uppername(obj):
return obj.name.upper()
# assign this simple function to an attribute of our class
rec.method = uppername
# Now it's a class's method!
>>> x.method()
'SUE'
>>> y.method() # Same, but pass y to self
'BOB'
CHAPTER 28 A More Realistic Example
It’s often more convenient to code tests in the same module's file as the items to be tested. It would be better not to let the test to be run when the file is imported. That’s exactly what the module __name__ check is designed for
if __name__ == '__main__': # When run for testing only
# self-test code start here, execute only if run as a script
- __repr__(self) A __repr__ method takes exactly one parameter, self, and must return a string. This string is intended to be a representation of the object. __repr__ will be called anytime the builtin repr function is applied to an object; this function is also called when the backquote operator is used.
- __str__(self) The __str__ method is exactly like __repr__ except that it is called when the builtin str function is applied to an object; this function is also called for the %s escape of the % operator.
We can see the effect of the overloading operator:
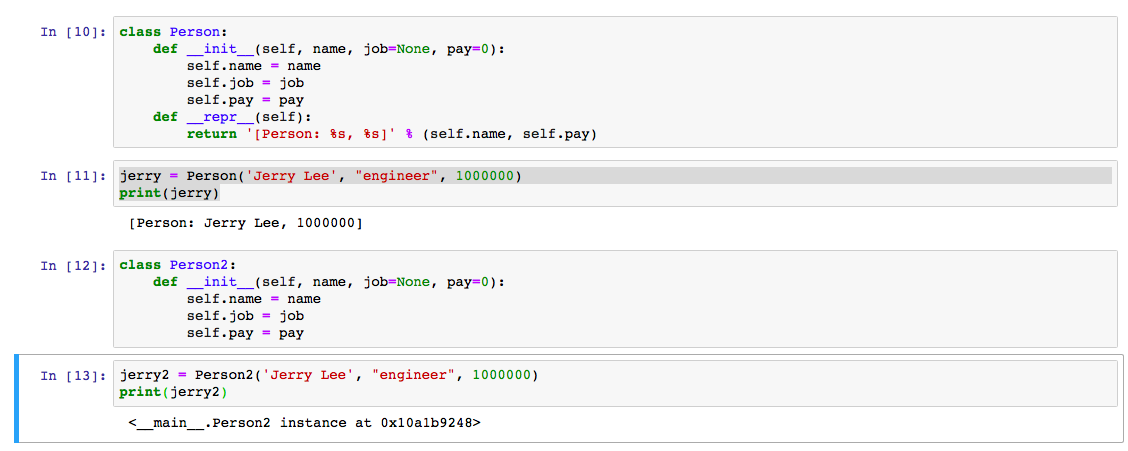
Another important attribute of an object-oriented programming language is polymorphism: the ability to use the same syntax for objects of different types.
We can use the __get attr__ operator overloading method to intercept undefined attribute fetches and delegate them to the embedded object with the getattr built-in.
- __getattr__(self, name) This method, if defined, is called when attribute lookup fails. For example,
class foo:
a = 0
def __getattr__(self, name):
return "%s: not defined" % name
i = foo()
i.b = 1
i.c
'c: not defined'
Object persistence is implemented by three standard library modules, available in every Python:
- pickle Serializes arbitrary Python objects to and from a string of bytes.
import pickle
# Pickling files
dogs_dict = { 'Ozzy': 3, 'Filou': 8, 'Luna': 5, 'Skippy': 10, 'Barco': 12, 'Balou': 9, 'Laika': 16 }
filename = 'dogs'
outfile = open(filename,'wb')
pickle.dump(dogs_dict,outfile)
outfile.close()
# Unpickling files
infile = open(filename,'rb')
new_dict = pickle.load(infile)
infile.close()
Storing Objects on a Shelve Database
The shelve module provides an extra layer of structure that allows you to store pickled objects by key.
shelve translates an object to its pickled string with pickle and stores that string under a key in a dbm file; when later loading, shelve fetches the pickled string by key and re-creates the original object in memory with pickle.
import shelve
db = shelve.open('persondb') # Filename where objects are stored
for obj in (bob, sue, tom): # Use object's name attr as key
db[obj.name] = obj # Store object on shelve by key
db.close() # Close after making changes
import pickle
# Pickling files
dogs_dict = { 'Ozzy': 3, 'Filou': 8, 'Luna': 5, 'Skippy': 10, 'Barco': 12, 'Balou': 9, 'Laika': 16 }
color_list = ["red", "green", "blue"]
axis_tuple = tuple(["x", "y", "z"])
filename = 'pickle_test'
outfile = open(filename,'wb')
pickle.dump(dogs_dict,outfile)
pickle.dump(axis_tuple,outfile)
pickle.dump(color_list,outfile)
outfile.close()
# Unpickling files
infile = open(filename,'rb')
try:
while (1):
obj = pickle.load(infile)
print(obj)
except:
print("EOF")
infile.close()
---
{'Ozzy': 3, 'Barco': 12, 'Laika': 16, 'Luna': 5, 'Filou': 8, 'Skippy': 10, 'Balou': 9}
('x', 'y', 'z')
['red', 'green', 'blue']
EOF
---
import shelve
db = shelve.open('shelve_test')
db["dogs"] = dogs_dict
db["axis"] = axis_tuple
db["color"] = color_list
db.close()
db = shelve.open('shelve_test')
len(db)
list(db.keys())
for key in db.keys():
print(key,":", db[key])
db.close()
---
('dogs', ':', {'Ozzy': 3, 'Barco': 12, 'Laika': 16, 'Luna': 5, 'Filou': 8, 'Skippy': 10, 'Balou': 9})
('color', ':', ['red', 'green', 'blue'])
('axis', ':', ('x', 'y', 'z'))
---
PART VII Exceptions and Tools
CHAPTER 33 Exception Basics
There are (at least) two distinguishable kinds of errors: syntax errors and exceptions.
Errors detected during execution are called exceptions and are not unconditionally fatal.
In Python, exceptions are triggered automatically on errors, and they can be triggered and intercepted by your code.
If your code does not explicitly catch this exception, it filters back up to the top level of the program and invokes the default exception handler, which simply prints the standard error message.
If you don’t want the default exception behavior, wrap the call in a try statement to catch exceptions yourself:
try:
...
except SomeException:
...
The try statement works as follows.
- the try clause (the statement(s) between the try and except keywords) is executed. If no exception occurs, the except clause is skipped and execution of the try statement is finished.
- If an exception occurs during execution of the try clause, the rest of the clause is skipped.
- if its type matches the exception named after the except keyword the except clause is executed, and then execution continues after the try statement.
- if an exception occurs which does not match the exception named in the except clause it is passed on to outer try statements;
- if no handler is found, it is an unhandled exception and execution stops with a message. if they’re not caught, exceptions are propagated up to the top-level default exception handler and terminate the program with a standard error message:
- An except clause may name multiple exceptions as a parenthesized tuple
- The last except clause may omit the exception name(s), to serve as a wildcard.
- The try … except statement has an optional else clause It is useful for code that must be executed if the try clause does not raise an exception.
except (RuntimeError, TypeError, NameError):
pass
try:
...
except OSError as err:
print("OS error: {0}".format(err))
except:
print("Unexpected error:", sys.exc_info()[0])
raise
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except OSError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
When an exception occurs, it may have an associated value, also known as the exception’s argument.
The except clause may specify a variable after the exception name. The variable is bound to an exception instance with the arguments stored in instance.args. For convenience, the exception instance defines __str__() so the arguments can be printed directly without having to reference .args.
>>> try:
... raise Exception('spam', 'eggs')
... except Exception as inst:
... print(type(inst)) # the exception instance
... print(inst.args) # arguments stored in .args
... print(inst) # __str__ allows args to be printed directly,
... # but may be overridden in exception subclasses
... x, y = inst.args # unpack args
... print('x =', x)
... print('y =', y)
...
('spam', 'eggs')
('spam', 'eggs')
x = spam
y = eggs
The as is optional in a try handler (if it’s omitted, the instance is simply not assigned to a name), but including it allows the handler to access both data in the instance and methods in the exception class.
Exceptions can be raised by Python(due to mistakes) or by your program, and can be caught or not. To trigger an exception manually, simply run a raise statement.
User-defined exceptions are coded with classes, which inherit from a built-in exception class: Exception:
class AlreadyGotOne(Exception): pass
try:
raise AlreadyGotOne()
except AlreadyGotOne:
print('already got one exception')
try/finally combinations come in handy to guarantee that termination actions will fire regardless of any exceptions that may occur in the try block’s code.
try:
work()
finally:
print('after work')
print('is work done?')
The with/as statement runs an object’s context management logic to guarantee that termination actions occur, irrespective of any exceptions in its nested block:
with open('lumberjack.txt', 'w') as file: # Always close file on exit
file.write('The larch!\n')
CHAPTER 34 Exception Coding Details
In Python, all exceptions must be instances of a class that derives from BaseException.
The built-in exception classes can be subclassed to define new exceptions; programmers are encouraged to derive new exceptions from the Exception class or one of its subclasses, and not from BaseException.
try:
statements # Run this main action first
except name1:
statements # Run if name1 is raised during try block
except (name2, name3):
statements # Run if any of these 2 exceptions occur
except name4 as var:
statements # Run if name4 is raised, assign instance raised to var
except:
statements # Run for all other exceptions raised
else:
statements # Run if no exception was raised during try block
finally:
statements # Run always
A finally clause is always executed before leaving the try statement,
- the block under the try header in this statement represents the main action
- The except clauses define handlers for exceptions raised during the try block
- the else clause (if coded) provides a handler to be run if no exceptions occur.
def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("division by zero!")
else:
print("result is", result)
finally:
print("executing finally clause")
divide(2, 1)
result is 2.0
executing finally clause
divide(2, 0)
division by zero!
executing finally clause
divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "", line 1, in
File "", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
To trigger exceptions explicitly, you can code raise statement in one of the following forms:
- raise instance Raise instance of class. This is the commonly used form.
- raise class Make then raise instance of class.
- raise Re-raise the most recent exception. The most recently raised exceptionThe is re-raised ; it’s commonly used in exception handlers to propagate exceptions that have been caught.
Exceptions are always identified by class instance objects, once caught by an except clause anywhere in the program, an exception dies (i.e., won’t propagate to another try), unless it’s re-raised by another raise statement or error.
For debugging purposes, Python includes the assert statement.
An assert can be thought of as a conditional raise statement:
if __debug__:
if not test:
raise AssertionError(data)
The above code can be implemented via the following assert statement:
assert test, data
assert statements may be removed from a compiled program’s byte code if the -O Python command-line flag is used, thereby optimizing the program.
with/as Context Managers
This statement is designed to work with context manager objects.
In short, the with/as statement is designed to be an alternative to a common try/ finally usage idiom; like that statement, with is in large part intended for specifying termination-time or “cleanup” activities that must run regardless of whether an exception occurs during a processing step.
with expression [as variable]:
with-block
- startup code before the with-block is started
- termination code after the with-block is done
- file
with open(r'C:\misc\data') as myfile:
for line in myfile:
print(line)
...more code here.
lock = threading.Lock() # After: import threading
with lock:
# critical section of code
...access shared resources...
The Context Management Protocol
To implement context managers, classes use special methods that fall into the operator overloading category to tap into the with statement.
Here’s how the with statement actually works:
- The expression is evaluated, resulting in an object known as a context manager that must have __enter__ and __exit__ methods.
- The context manager’s __enter__ method is called. The value it returns is assigned to the variable in the as clause if present, or simply discarded otherwise.
- The code in the nested with block is executed.
- If the with block raise an exception, the __exit__(type,value,traceback) method is called with the exception details.
- If the with block does not raise an exception, the __exit__ method is still called, but its type, value, and traceback arguments are all passed in as None.
PART VIII Advanced Topics
CHAPTER 37 Unicode and Byte Strings
For ASCII test, Python’s basic str string type and its associated operations are good with.
As non-ASCII character sets, Unicode text and binary data, the advanced string representation is needed.
String Basics
Character sets are standards that assign integer codes to individual characters.
For example, the ASCII standard maps the character 'a' to the integer value 97 (0x61 in hex).
To accommodate special characters which are outside the ASCII set(0~127 for characters, 128~255 for extended control codes) and can not be represented as one byte, Unicode is developed to represent a character with multiple bytes if needed. The encoding name is used to identify which translation should be used for the multi-byte characters.
- UTF-8 encoding It uses a variable-sized number of bytes scheme:
- character codes less than 128 are represented as a single byte
- character codes between 128 and 0x7ff (2047) are turned into 2 bytes Each byte has a value between 128 and 255
- character codes above 0x7ff are turned into 3 or 4 bytes sequences Each byte has a value between 128 and 255
- UTF-16 encoding
>>> test_str = 'ok'
>>> test_str.encode('ascii'), len(test_str.encode('ascii'))
('ok', 2)
>>> test_str.encode('utf8'), len(test_str.encode('utf8'))
('ok', 2)
>>> test_str.encode('utf16'), len(test_str.encode('utf16'))
('\xff\xfeo\x00k\x00', 6)
>>> test_str.encode('utf32'), len(test_str.encode('utf32'))
('\xff\xfe\x00\x00o\x00\x00\x00k\x00\x00\x00', 12)
>>> import encodings
>>> help(encodings)
Python's built-in functions to investigate characters:
- ord(c) Given a string of length one, return an integer representing the Unicode code point of the character when the argument is a unicode object, or the value of the byte when the argument is an 8-bit string.
>>> ord('a')
97
>>> ord(u'\u2020')
8224
>>> chr(97)
'a'
>>> unichr(97)
u'a'
>>> unichr(8224)
u'\u2020'
Text is translated to and from an encoding-specific format only when it is transferred to or from external text files, byte strings.
Once in memory, strings have no encoding, they are just the string object.
String data type provided in the Python 3.x script:
- str for representing decoded Unicode text (including ASCII)
- byte for representing binary data (including encoded text)
- bytearray a mutable flavor of the bytes type
Text and Binary Files
Python now makes a sharp platform-independent distinction between text files and binary files; in 3.X:
- Text files When a file is opened in text mode, reading its data automatically decodes its content and returns it as a str; writing takes a str and automatically encodes it before transferring it to the file.
- Binary files When a file is opened in binary mode, reading its data does not decode it in any way but simply returns its content raw and unchanged, as a bytes object; writing similarly takes a bytes object and transfers it to the file unchanged.
Coding Basic Strings
In Python 3.X, string objects is originated by:
- when you call a built-in function such as str or bytes
- read a file created by calling open
- code literal syntax 'xxx', "xxx", and triple- quoted blocks; adding a b or B just before any of them creates a bytes instead.
and, str and bytes type objects can not be mixed automatically in expressions.
You need to do explicit conversions when needed:
- str.encode() and bytes(S, encoding) translate a string to its raw bytes form
- bytes.decode() and str(B, encoding) translate raw bytes into its string form
>>> import sys
>>> sys.platform
'darwin'
>>> sys.getdefaultencoding()
'ascii'
Coding Unicode Strings
Encoding and decoding become more meaningful when you start dealing with non- ASCII Unicode text.
Python string literals support 3 unicode escape:
- 1-byte (8-bit) hex value escape "\xNN"
- 2-byte (16-bit) hex vale escape "\uNNNN"
- 4-byte (32-bit) hex value escape "\UNNNNNNNN"
Using Text and Binary Files
The mode in which you open a file is crucial — it determines which object type you will use to represent the file’s content in your script.
Text mode implies str objects, and binary mode implies bytes objects:
>>> file = open('temp', 'w')
>>> size = file.write('abc\n') # Returns number of characters written
>>> file.close() # Manual close to flush output buffer
>>> file = open('temp') # Default mode is "r" (== "rt"): text input
>>> text = file.read()
>>> text
'abc\n'
>>> print(text)
abc
The only major difference between text and binary modes is that text files automatically map \n end-of-line characters to and from \r\n on Windows, while binary files do not.
C:\code> C:\python27\python
>>> open('temp', 'w').write('abd\n') # Write in text mode: adds \r
>>> open('temp', 'r').read() # Read in text mode: drops \r
'abd\n'
>>> open('temp', 'rb').read() # Read in binary mode: verbatim
'abd\r\n'
>>> open('temp', 'wb').write('abc\n') # Write in binary mode
>>> open('temp', 'r').read() # \n not expanded to \r\n
'abc\n'
>>> open('temp', 'rb').read()
'abc\n'
Using Unicode Files
We can effectively convert a string to different encoded forms:
- Create a unicode string
>>> S = 'A\xc4B\xe8C' # Five-character decoded string, non-ASCII
>>> S
'AÄBèC'
>>> len(S)
5
>>> L = S.encode('latin-1') # 5 bytes when encoded as latin-1
>>> L
b'A\xc4B\xe8C'
>>> len(L)
5
>>> U = S.encode('utf-8') # 7 bytes when encoded as utf-8
>>> U
b'A\xc3\x84B\xc3\xa8C'
>>> len(U)
7
>>> open('latindata', 'w', encoding='latin-1').write(S) # Write as latin-1
5
>>> open('utf8data', 'w', encoding='utf-8').write(S) # Write as utf-8
5
>>> open('latindata', 'rb').read() # Read raw bytes
b'A\xc4B\xe8C'
>>> open('utf8data', 'rb').read() # Different in files
b'A\xc3\x84B\xc3\xa8C'
>>> open('latindata', 'r', encoding='latin-1').read() # Decoded on input
'AÄBèC'
>>> open('utf8data', 'r', encoding='utf-8').read() # Per encoding type
'AÄBèC'
>>> X = open('latindata', 'rb').read() # Manual decoding:
>>> X.decode('latin-1') # Not necessary
'AÄBèC'
>>> X = open('utf8data', 'rb').read()
>>> X.decode() # UTF-8 is default
'AÄBèC'
Handling the BOM
Some encoding schemes store a special byte order marker (BOM) sequence at the start of files, to specify data endianness or declare the encoding type.
For instance:
• In UTF-16, the BOM is always processed for “utf-16,” and the more specific encoding name “utf-16-le” denotes little-endian format.
• In UTF-8, the more specific encoding “utf-8-sig” forces Python to both skip and write a BOM on input and output, respectively, but the general “utf-8” does not.
Unicode Filenames and Streams
The filename and filesystem have their own encoding:
import sys
sys.getdefaultencoding(), sys.getfilesystemencoding()
re — Regular expression operations Module
The module re provides full support for Perl-like regular expressions in Python.
A regular expression is a special sequence of characters that helps you match or find other strings or sets of strings, using a specialized syntax held in a pattern.
Except for control characters, (+ ? . * ^ $ ( ) [ ] { } | \), all characters match themselves. You can escape a control character by preceding it with a backslash.
The regular expression syntax that is available in Python:
- ^
Matches beginning of line.
- $
Matches end of line.
- .
Matches any single character except newline. Using m option allows it to match newline as well.
- [...]
Matches any single character in brackets.
- [^...]
Matches any single character not in brackets
- re*
Matches 0 or more occurrences of preceding expression.
- re+
Matches 1 or more occurrence of preceding expression.
- re?
Matches 0 or 1 occurrence of preceding expression.
- re{ n}
Matches exactly n number of occurrences of preceding expression.
- re{ n,}
Matches n or more occurrences of preceding expression.
- re{ n, m}
Matches at least n and at most m occurrences of preceding expression.
- a| b
Matches either a or b.
- (re)
Groups regular expressions and remembers matched text.
- (?imx)
Temporarily toggles on i, m, or x options within a regular expression. If in parentheses, only that area is affected.
- (?-imx)
Temporarily toggles off i, m, or x options within a regular expression. If in parentheses, only that area is affected.
- (?: re)
Groups regular expressions without remembering matched text.
- (?imx: re)
Temporarily toggles on i, m, or x options within parentheses.
- (?-imx: re)
Temporarily toggles off i, m, or x options within parentheses.
- (?#...)
Comment.
-
(?= re)
Specifies position using a pattern. Doesn't have a range.
- (?! re)
Specifies position using pattern negation. Doesn't have a range.
- (?> re)
Matches independent pattern without backtracking.
- \w
Matches word characters.
- \W
Matches nonword characters.
- \s
Matches whitespace. Equivalent to [\t\n\r\f].
- \S
Matches nonwhitespace.
- \d
Matches digits. Equivalent to [0-9].
- \D
Matches nondigits.
- \A
Matches beginning of string.
- \Z
Matches end of string. If a newline exists, it matches just before newline.
- \z
Matches end of string.
- \G
Matches point where last match finished.
- \b
Matches word boundaries when outside brackets. Matches backspace (0x08) when inside brackets.
- \B
Matches nonword boundaries.
- \n, \t, etc.
Matches newlines, carriage returns, tabs, etc.
- \1...\9
Matches nth grouped subexpression.
- \10
Matches nth grouped subexpression if it matched already. Otherwise refers to the octal representation of a character code.
Regular Expression Examples:
- Literal characters
- python Match "python".
- Character classes
- [Pp]ython Match "Python" or "python"
- [^0-9] Match anything other than a digit
The pickle Object Serialization Module
Keep in mind that always use binary-mode files for pickled data.
>>> import pickle
>>> pickle.dump([1, 2, 3], open('temp', 'wb')) # Version neutral
>>> pickle.load(open('temp', 'rb')) # And required in 3.X
[1, 2, 3]

留言