Linux Device Drivers - I
Linux Device Drivers
Jonathan Corbet, Alessandro
Rubini, and Greg Kroah-Hartman

Content:
- 1. An Introduction to Device Drivers
- 2. Building and Running Modules
- 3. Char Drivers
CHAPTER 1 An Introduction to Device Drivers
Security Issues
In the official kernel distribution, only an authorized user can load modules; the system call init_module checks if the invoking process is authorized to load a module into the kernel.Joining the Kernel Development Community
Follow the instructions found in the linux-kernel mailing list FAQ: http://www.tux.org/lkml.
All the programs in this book are available at ftp://ftp.ora.com/pub/examples/linux/drivers/,
Chapter 2: Building and Running Modules
Setting Up Your Test System
Obtain a “main-line” kernel directly from the kernel.org mirror network is preferred because vendor patches can change the kernel API sometimes.
A current set of header files is sufficient for building modules, modules are linked against object files found in the kernel source tree.
So your first order of business is to come up with a kernel source tree , build a new kernel, and install it on your system.
The Hello World Module
#include <linux/init.h>
#include <linux/module.h>
MODULE_LICENSE("Dual BSD/GPL");
static int hello_init(void)
{
printk(KERN_ALERT "Hello, world\n");
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT "Goodbye, cruel world\n");
}
module_init(hello_init);
module_exit(hello_exit);
- macro MODULE_LICENSE is used to tell the kernel that this module bears a free license; without such a declaration, the kernel complains when the module is loaded. When the kernel is tainted, it means that it is in a state that is not supported by the community.
- module_init and module_exit lines use special kernel macros to indicate the functions to be called when the module is loaded or removed
- The printk() dumps messages on a text console; you won’t see anything on your screen when a terminal emulator is used under the window system. The message goes to one of the system log files, such as /var/log/messages
Note that there is NO comma between the KERN_ERR and the format string (as the preprocessor concatenates both strings).
The log levels are defined in include/linux/kern_levels.h:
/* integer equivalents of KERN_LEVEL */ #define LOGLEVEL_SCHED -2 /* Deferred messages from sched code * are set to this special level */ #define LOGLEVEL_DEFAULT -1 /* default (or last) loglevel */ #define LOGLEVEL_EMERG 0 /* system is unusable */ #define LOGLEVEL_ALERT 1 /* action must be taken immediately */ #define LOGLEVEL_CRIT 2 /* critical conditions */ #define LOGLEVEL_ERR 3 /* error conditions */ #define LOGLEVEL_WARNING 4 /* warning conditions */ #define LOGLEVEL_NOTICE 5 /* normal but significant condition */ #define LOGLEVEL_INFO 6 /* informational */ #define LOGLEVEL_DEBUG 7 /* debug-level messages */
To determine your current console_loglevel you simply enter:
$ cat /proc/sys/kernel/printk 7 4 1 7 current default minimum boot-time-default
The first integer shows you your current console_loglevel; the second the default log level that you have seen above.
To change your current console_loglevel simply write to this file, so in order to get all messages printed to the console do a simple
# echo 8 > /proc/sys/kernel/printk
In addition, some debugging functionality and API calls may be disabled when the kernel is tainted.
Some oops reports contain the string ‘Tainted: ‘ after the program counter. This indicates that the kernel has been tainted by some mechanism. The string is followed by a series of position-sensitive characters, each representing a particular tainted value.
Kernel Modules Versus Applications
Application starts and ends in the same context.But:
- Every kernel module just registers itself in order to serve future requests, and its initialization function terminates immediately.
- The task of the module’s initialization function is to prepare for later invocation of the module’s functions
- The module’s exit function gets invoked just before the module is unloaded, the exit function of a module must carefully undo everything the init function built up
- A module is linked only to the kernel, and the only functions it can call are the ones exported by the kernel; there are no libraries to link to.
User Space and Kernel Space
All current processors have at least two protection levels.
Under Unix/Linux,
- kernel space the kernel executes in the highest level (also called supervisor mode), where everything is allowed.
- user space applications execute in the lowest level (the so-called user mode), where the processor regulates direct access to hardware and unauthorized access to memory.
- system calls Kernel code executing a system call is working in the context of a process.
- interrupts not related to any particular process.
Each time a process is removed from access to the processor, sufficient information on its current operating state must be stored such that when it is again scheduled to run on the processor it can resume its operation from an identical position. This operational state data is known as its context and the act of removing the process's thread of execution from the processor (and replacing it with another) is known as a process switch or context switch.
Concurrency in the Kernel
Kernel code has been made preemptible; this change causes even uniprocessor systems to have many of the same concurrency issues as multiprocessor systems.
As a result, Linux kernel code, including driver code, must be reentrant — it must be capable of running in more than one context at the same time.
Driver development must be with concurrency in mind: kernel code can(almost) never assume that it can hold the processor over a given stretch of code
The Current Process
Most actions performed by the kernel are done on behalf of a specific process. Kernel code can refer to the current process by accessing the global item current which is a pointer to struct task_struct, defined by <linux/sched.h>.
To support SMP systems, the kernel developers to develop a mechanism that finds the current process on the relevant CPU very fast. That is an architecture-dependent mechanism.
The following statement prints the process ID and the command name of the current process
printk(KERN_INFO "The process is \"%s\" (pid %i)\n", current->comm, current->pid);
A Few Other Details
Kernel stack is small, driver functions should allocate data structures dynamically at call time as possible.
Function names starting with a double underscore (__) are low-level.
Compiling and Loading
Compiling Modules
The kernel build system is a complex beast, Documentation/kbuild in the kernel source are required reading to understand all that is really going on beneath the surface.
Most Makefiles within the kernel are kbuild Makefiles that use the kbuild infrastructure.
The preferred name for the kbuild files are ‘Makefile’ but ‘Kbuild’ can be used and if both a ‘Makefile’ and a ‘Kbuild’ file exists, then the ‘Kbuild’ file will be used.
The kernel source makes a great many assumptions about the compiler, the file Documentation/Changes in the kernel documentation directory always lists the required tool versions.
You need the kernel source tree to build your kernel module.
The kernel build system handles the build flow if you follow its makefile template and it must be invoked within the context of the larger kernel build system.
- Built-in object goals: obj-y
obj-y := file1.o
The kbuild Makefile specifies object files for vmlinux in the $(obj-y) lists.Kbuild compiles all the $(obj-y) files. It then calls “$(AR) rcSTP” to merge these files into one built-in.a file. This is a thin archive without a symbol table. It will be later linked into vmlinux by scripts/link-vmlinux.sh.
A module may be built from one source file or several source files.
- one source file
obj-m += file.o
obj-m += module_name.o
module_name-y := file_1.o file_2.o file_3.o
If your kernel source tree is located in, say, $(KERNELDIR), the make command required to build your module (typed in the directory containing the module source and makefile) would be:
make -C $(KERNELDIR) M=`pwd` modules
where- -C Change to the kernel source directory so that it can find the the kernel's top level makefile.
- M= Move back to your module source directory before building your module target (assigned by obj-m)
- KBUILD_EXTRA_SYMBOLS When an external module is built, a Module.symvers file is generated containing all exported symbols which are not defined in the kernel. You can assign a space separated list of files to KBUILD_EXTRA_SYMBOLS in your makefile to get access to symbols from other Module.symvers files. These files will be loaded by modpost during the initialization of its symbol tables.
# If KERNELRELEASE is defined, we've been invoked in the kernel build system
ifneq ($(KERNELRELEASE),)
obj-m := hello.o
# Otherwise we were called directly from the command line
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
endif
It locates the kernel source directory by taking advantage of the fact that the symbolic link build in the installed modules directory points back at the kernel build tree./lib/modules/4.10.0-19-generic/build -> /usr/src/linux-headers-4.10.0-19-genericIn Ubuntu 18.04:
/lib/modules/5.0.0-36-generic/build -> /usr/src/linux-headers-5.0.0-36-generic /usr/src/linux-headers-5.0.0-36-generic/Module.symvers
Loading and Unloading Modules
The kernel executes at the highest level of privilege mode, and allows applications to request services via system calls.
A system call is the programmatic way in which a computer application requests a service from the kernel.
System calls in most Unix-like systems are processed in kernel mode, which is accomplished by changing the processor execution mode to a more privileged one, but no process context switch is necessary

insmod relies on a system call sys_init_module() defined in kernel/module.c:
- allocates kernel memory to hold a module
- copies the module text into that memory region
- resolves kernel references in the module via the kernel symbol table
- calls the module’s initialization function
modprobe, like insmod, loads a module into the kernel. It differs in that:
- it will look at the module to be loaded to see whether it references any symbols that are not currently defined in the kernel.
- If any such references are found, modprobe looks for other modules in the current module search path that define the relevant symbols.
- When modprobe finds those modules (which are needed by the module being loaded), it loads them into the kernel as well.
Information on currently loaded modules can also be found in the sysfs virtual filesystem under /sys/module.
Version Dependency
One of the steps in the build process is to link your module against a file(called vermagic.o)from the current kernel tree.
When an attempt is made to load a module, this information can be tested for compatibility with the running kernel.
You likely have to make use of macros and #ifdef constructs to make your code build properly.
For ex.,,
#include <generated/uapi/linux/version.h> #if LINUX_VERSION_CODE < KERNEL_VERSION(4,11,0) #include <linux/signal.h> #else #include <linux/sched/signal.h> #endif
- old kernel releases This header file, linux/version.h, automatically included by linux/module.h, defines the following macros:
- UTS_RELEASE This macro expands to a string describing the version of this kernel tree. For example, "2.6.10".
- LINUX_VERSION_CODE This macro expands to the binary representation of the kernel version, one byte for each part of the version release number. For example, the code for 2.6.10 is 132618(i.e.,0x02060a).With this information, you can(almost) easily determine what version of the kernel you are dealing with.
- KERNEL_VERSION(major,minor,release) This is the macro used to build an integer version code from the individual numbers that build up a version number. For example, KERNEL_VERSION(2,6,10) expands to 132618. This macro is very useful when you need to compare the current version and a known checkpoint.
- recent kernel releases The file "include/generated/uapi/linux/version.h" defines the kernel version information:
#define LINUX_VERSION_CODE 327701 #define KERNEL_VERSION(a,b,c) (((a) << 16) + ((b) << 8) + (c))
The Kernel Symbol Table
When a module is loaded, any symbol exported by the module becomes part of the kernel symbol table.You need to export symbols, however, whenever other modules may benefit from using them. Module stacking is useful in complex projects. You can split your driver into a generic module that exports symbols used by lower-level device drivers for specific hardware. When using stacked modules, it is helpful to be aware of the modprobe utility. It loads any other modules that are required by the module you want to load. If your module needs to export symbols for other modules to use, the following macros should be used.
EXPORT_SYMBOL(name);
EXPORT_SYMBOL_GPL(name);
This exported variable is stored in a special part of the module executible(an “ELF section”) that is used by the kernel at load time to find the variables exported by the module. The _GPL version makes the symbol available to GPL-licensed modules only. Preliminaries
All module code has the following:
#include <linux/module.h>
#include <linux/init.h>
A relatively recent convention in kernel code is to put the following MODULE_ declarations at the end of the file: - MODULE_LICENSE("GPL")
- MODULE_AUTHOR (stating who wrote the module)
- MODULE_DESCRIPTION (a human-read- able statement of what the module does)
- MODULE_VERSION (for a code revision number)
- MODULE_ALIAS (another name by which this module can be known)
- MODULE_DEVICE_TABLE (to tell user space about which devices the module sup- ports) MODULE_DEVICE_TABLE will export informations to user space that will be collected by depmod to update the modules.alias file, thus allowing the driver to be automatically found and loaded if it is build as module.
Initialization and Shutdown
The module initialization function registers any facility offered by the module so that an application can access. The initialization function always looks like:static int __init initialization_function(void) { /* Initialization code here */ } module_init(initialization_function);
- The __init token in the definition is a hint to the kernel that the given function is used only at initialization time.( related functions are put in the section .init.text ) include/linux/init.h:
/* These macros are used to mark some functions or * initialized data (doesn't apply to uninitialized data) * as `initialization' functions. The kernel can take this * as hint that the function is used only during the initialization * phase and free up used memory resources after * * Usage: * For functions: * * You should add __init immediately before the function name, like: * * static void __init initme(int x, int y) * { * extern int z; z = x * y; * } * * If the function has a prototype somewhere, you can also add * __init between closing brace of the prototype and semicolon: * * extern int initialize_foobar_device(int, int, int) __init; #define __init __section(.init.text) __cold __latent_entropy __noinitretpoline #define __initdata __section(.init.data) #define __initconst __section(.init.rodata) #define __exitdata __section(.exit.data) #define __exit_call __used __section(.exitcall.exit)include/linux/compiler.h:
#ifndef __latent_entropy #define __latent_entropy #endif #ifndef __cold #define __cold #endif #ifndef __section # define __section(S) __attribute__ ((__section__(#S))) #endifThe keyword __attribute__ allows you to specify special attributes of variables or structure fields. This keyword is followed by an attribute specification inside double parentheses:
- section ("section-name") Normally, the compiler places the objects it generates in sections like data and bss. If you need additional sections, , or you need certain particular variables to appear in special sections, the section attribute specifies that a variable (or function) lives in a particular section.
The Cleanup Function
Every nontrivial module also requires a cleanup function which is defined as the following template:
static void __exit cleanup_function(void) {
/* Cleanup code here */
}
module_exit(cleanup_function);
The __exit modifier marks the code as being for module unload only (by causing the compiler to place it in a special ELF section). The module_exit() declaration is necessary to enable to kernel to find your cleanup function. Error Handling During Initialization
The registration to kernel could fail, you must undo any registration activities performed before the failure. Careful use of goto in error situations can eliminate a complex logic of error handling. Example,
int __init my_init_function(void) {
int err;
/* registration takes a pointer and a name */
err = register_1(ptr1, "skull");
if (err)
goto fail_1;
err = register_2(ptr2, "skull");
if (err)
goto fail_2;
err = register_3(ptr3, "skull");
if (err)
goto fail_3;
return 0; /* success */
...
fail_3:
unregister_3(ptr2, "skull");
fail_2:
unregister_2(ptr1, "skull");
fail_1:
return err; /* propagate the error */
}
In the Linux kernel, error codes are negative numbers belonging to the set defined in <linux/errno.h>. User programs can turn the defined error codes to meaningful strings using perror or similar means. The module cleanup function must undo any registration performed by the initialization function. Example,
void __exit my_cleanup_function(void) {
unregister_3(ptr3, "skull");
unregister_2(ptr2, "skull");
unregister_1(ptr1, "skull");
return;
}
To avoid the code duplications, the __init and __exit functions can be implemented to use the same clean up function as the code template:
struct something *item1;
struct somethingelse *item2;
int stuff_ok;
void my_cleanup(void)
{
if (item1)
release_thing(item1);
if (item2)
release_thing2(item2);
if (stuff_ok)
unregister_stuff( );
return;
}
int __init my_init(void)
{
int err = -ENOMEM;
item1 = allocate_thing(arguments);
item2 = allocate_thing2(arguments2);
if (!item2 || !item2)
goto fail;
err = register_stuff(item1, item2);
if (!err)
stuff_ok = 1;
else
goto fail;
return 0; /* success */
fail:
my_cleanup( );
return err;
}
Module-Loading Races
After the initialization, the module has clearly succeeded in exporting something useful.Do not register any kernel facility until all of your internal initialization needed to support that facility has been completed.
Module Parameters
A driver may need to know several parameters which may change from system to system. For ex., I/O ports or memory address. These parameter values can be assigned at load time by insmod or modprobe. Parameters are declared with the module_param macro( defined in moduleparam.h ). module_param(name, type, perm) takes three parameters:- the name of the variable
- parameter's type
- bool A boolean(true or false) value (the associated variable should be of type int).
- invbool The invbool type inverts the value, so that true values become false and vice versa.
- charp A char pointer value. Memory is allocated for user-provided strings, and the pointer is set accordingly.
- int
- long
- short
- uint
- ulong
- ushort
- a permissions mask to be used for an accompanying sysfs entry The definitions can be found in <linux/stat.h>. This value controls who can access the representation of the module parameter in sysfs.
- S_IRUGO a parameter that can be read by the world but cannot be changed
- S_IRUGO|S_IWUSR allows root to change the parameter.
module_param_array(name,type,num,perm);
All module parameters should be given a default value; insmod changes the value only if explicitly told to by the user.
It is possible to have the internal variable named differently than the external parameter. This is accomplished via :
module_param_named(name, variable, type, perm);where name is the externally viewable parameter name and variable is the name of the internal global variable. For example,
static unsigned int max_test = DEFAULT_MAX_LINE_TEST; module_param_named(maximum_line_test, max_test, int, 0);
Ex.,
#include <linux/init.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
MODULE_LICENSE("Dual BSD/GPL");
static char *whom = "world";
static int howmany = 1;
module_param(howmany, int, S_IRUGO);
module_param(whom, charp, S_IRUGO);
static int hello_init(void)
{
int i;
for (i = 0; i < howmany; i++)
printk(KERN_ALERT "(%d) Hello, %s\n", i, whom);
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT "Goodbye, cruel world\n");
}
module_init(hello_init);
module_exit(hello_exit)
$ sudo insmod hellop.ko howmany=3
$ sudo cat /sys/module/hellop/parameters/howmany
3
$ sudo cat /sys/module/hellop/parameters/whom
world
Doing It in User Space
Usually, the writer of a user-space driver implements a server process, taking over from the kernel the task of being the single agent in charge of hardware control.THIS_MODULE
Whenever you create a kernel module, the kernel's build machinery generates a struct module object for you, and makes THIS_MODULE point to it. linux/module.h:
struct module {
...
/* Unique handle for this module */
char name[MODULE_NAME_LEN];
/* Sysfs stuff. */
struct module_kobject mkobj;
struct module_attribute *modinfo_attrs;
const char *version;
...
};
This struct contains many fields, some of which can be set with module macros such as MODULE_VERSION.This example shows how to access that information:
/* Set by default based on the module file name. */
pr_info("name = %s\n", THIS_MODULE->name);
pr_info("version = %s\n", THIS_MODULE->version);
Summary in an Example
Makefile
KERNELDIR ?= /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) obj-m := test.o test-y := hello.o default: $(MAKE) -C $(KERNELDIR) M=$(PWD) modules
Driver
hello.c:
#include <linux/init.h>
#include <linux/module.h>
MODULE_LICENSE("Dual BSD/GPL");
static int __init hello_init(void)
{
printk(KERN_ALERT "Hello\n");
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_ALERT "Bye\n");
}
module_init(hello_init);
module_exit(hello_exit);
Test
- make
make -C /lib/modules/4.10.0-42-generic/build M=/home/jerry/ldd/test modules make[1]: Entering directory '/usr/src/linux-headers-4.10.0-42-generic' CC [M] /home/jerry/ldd/test/hello.o LD [M] /home/jerry/ldd/test/test.o Building modules, stage 2. MODPOST 1 modules CC /home/jerry/ldd/test/test.mod.o LD [M] /home/jerry/ldd/test/test.ko make[1]: Leaving directory '/usr/src/linux-headers-4.10.0-42-generic'
sudo insmod test.ko
sudo rmmod test.ko
tail /var/log/syslog Nov 12 10:43:53 jerry-VirtualBox kernel: [ 690.923936] Hello Nov 12 10:44:00 jerry-VirtualBox kernel: [ 697.764152] Bye
How to load a kernel module automatically at boot time
Config file
The file /etc/modules (or other files in /etc/modules-load.d/) is used if new hardware is added after installation and the hardware requires a kernel module, the system must be configured to load the proper kernel module for the new hardware.Kernel modules can be explicitly listed in files under /etc/modules-load.d/ for systemd to load them during boot. Each configuration file is named in the style of
/etc/modules-load.d/<program>.confConfiguration files simply contain a list of kernel modules names to load, separated by newlines. Empty lines and lines whose first non-whitespace character is # or ; are ignored. For ex.,
- /etc/modules-load.d/cups-filters.conf
lp ppdev parport_pc
arp_tables br_netfilter ip6table_filter iptable_filter overlayTo check the status of module loading by systemd:
$ systemctl status systemd-modules-load
* systemd-modules-load.service - Load Kernel Modules
Loaded: loaded (/lib/systemd/system/systemd-modules-load.service; static; vendor preset: enabled)
Active: active (exited) since Thu 2021-02-25 15:14:16 CST; 3 weeks 4 days ago
Docs: man:systemd-modules-load.service(8)
man:modules-load.d(5)
Main PID: 416 (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 18771)
Memory: 0B
CGroup: /system.slice/systemd-modules-load.service
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'lp'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'ppdev'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'parport_pc'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'arp_tables'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'br_netfilter'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'ip6table_filter'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'iptable_filter'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd-modules-load[416]: Inserted module 'overlay'
Feb 25 15:14:16 jerry-NUC10i7FNH systemd[1]: Finished Load Kernel Modules.
Warning: journal has been rotated since unit was started, output may be incomplete.
Automatic module loading with udev
Today, all necessary modules loading is handled automatically by udev, so if you do not need to use any out-of-tree kernel modules, there is no need to put modules that should be loaded at boot in any configuration file.However, there are cases where you might want to load an extra module during the boot process, or blacklist another one for your computer to function properly.
Running the following is necessary after installing the module under the path /lib/modules/$(uname -r):
sudo depmoddepmod creates a list of module dependencies by reading each module under /lib/modules/$(uname -r) and determining what symbols it exports and what symbols it needs.
By default, this list is written to modules.dep, and a binary hashed version named modules.dep.bin, in the same directory.
depmod also creates a list of symbols provided by modules in the file named modules.symbols and its binary hashed version, modules.symbols.bin.
depmod will output a file named modules.devname if modules supply special device node that should be populated in /dev on boot (by a utility such as udev). The uevent message contains information about the device . event is just string of some special format that is sent via netlink socket. Example:
"add@/class/input/input9/mouse2\0 // message ACTION=add\0 // action type DEVPATH=/class/input/input9/mouse2\0 // path in /sys SUBSYSTEM=input\0 // subsystem (class) SEQNUM=1064\0 // sequence number PHYSDEVPATH=/devices/pci0000:00/0000:00:1d.1/usb2/22/22:1.0\0 // device path in /sys PHYSDEVBUS=usb\0 // bus PHYSDEVDRIVER=usbhid\0 // driver MAJOR=13\0 // major number MINOR=34\0", // minor numberThis information contains registered vendor and model identification for devices connected to buses such as PCI and USB.
Udev parses these events and constructs a fixed-form module name which it passes to modprobe.
modprobe looks under /lib/modules/$(uname -r) for a file called module.alias which is generated when the kernel is installed and that maps the fixed-form module names to actual driver module file names.
Debug
[ 61.642434] systemd[1]: Starting Load Kernel Modules... [ 61.842232] systemd[1]: Starting udev Coldplug all Devices... [ 61.982176] systemd[1]: Starting Uncomplicated firewall... [ 62.110444] systemd[1]: Started Journal Service. [ 63.410819] EXT4-fs (nvme0n1p3): re-mounted. Opts: (null) [ 64.039379] systemd-journald[406]: Received client request to flush runtime journal. [ 64.838864] igc: loading out-of-tree module taints kernel. [ 64.838937] igc: module verification failed: signature and/or required key missing - tainting kernel [ 64.839413] Intel(R) 2.5G Ethernet Linux Driver - version 0.0.1-k [ 64.839414] Copyright(c) 2018 Intel Corporation. [ 64.861628] dw-apb-uart.1: ttyS4 at MMIO 0x4017001000 (irq = 16, base_baud = 6250000) is a 16550A [ 64.878443] mei_me 0000:00:16.0: enabling device (0000 -> 0002) [ 64.894397] igc 0000:30:00.0 (unnamed net_device) (uninitialized): PHC added [ 64.934772] cfg80211: Loading compiled-in X.509 certificates for regulatory database [ 64.934973] cfg80211: Loaded X.509 cert 'sforshee: 00b28ddf47aef9cea7' [ 64.935238] Bluetooth: Core ver 2.22 [ 64.935256] NET: Registered protocol family 31 [ 64.935256] Bluetooth: HCI device and connection manager initialized [ 64.935259] Bluetooth: HCI socket layer initialized [ 64.935261] Bluetooth: L2CAP socket layer initialized [ 64.935264] Bluetooth: SCO socket layer initialized [ 64.955100] snd_hda_intel 0000:00:1f.3: DSP detected with PCI class/subclass/prog-if info 0x040100 [ 64.955317] snd_hda_intel 0000:00:1f.3: Digital mics found on Skylake+ platform, using SOF driver [ 64.965758] igc 0000:30:00.0: 4.000 Gb/s available PCIe bandwidth (5 GT/s x1 link) [ 64.965761] igc 0000:30:00.0 eth0: MAC: 8c:8c:aa:54:8d:2a [ 64.991503] Intel(R) Wireless WiFi driver for Linux
Chapter 3: Char Drivers
scull (Simple Character Utility for Loading Localities) is a char driver that acts on a memory area as though it were a device.The Design of scull
The following types of device drivers are implemented :- scull0 - scull3 Four devices, each consisting of a memory area that is both global and persistent.
- scullpipe0 - scullpipe3 Four FIFO (first-in-first-out) devices, which act like pipes.
- scullsingle allows only one process at a time to use the driver
- scullpriv private to each virtual console
- sculluid Return an error of “Device Busy” if another user is locking the devic
- scullwuid This implements blocking open
Major and Minor Numbers
Char devices are accessed through special files, called device files. For char drivers, device files are identified by a “c” in the first column of the output of ls –l. Traditionally,- the major number identifies the driver associated with the device.
- the minor number is used by the kernel to determine exactly which device(instance) is being referred to.
The Internal Representation of Device Numbers
Within the kernel, the dev_t type (defined in <linux/types.h>) is used to hold device numbers. To obtain the major or minor parts of a dev_t, use:
MAJOR(dev_t dev);
MINOR(dev_t dev);
MKDEV(int major, int minor);
Allocating and Freeing Device Numbers
There are 2 methods to obtain one or more device numbers to work with a device driver:
- manually assigned device numbers based on a known device number After you create the device number first,
int register_chrdev_region(dev_t first, unsigned int count, char *name);
where
- first the beginning device number of the range you would like to allocate. The minor number portion of first is often 0.
- count the total number of contiguous device numbers you are requesting
- name the name of the device which will appear in /proc/devices and sysfs(/sys/devices).
int alloc_chrdev_region(dev_t *dev, unsigned int firstminor,
unsigned int count, char *name);
With this function, dev is an output-only parameter assigned by the kernel. Regardless of how you allocate your device numbers, you should free them when they are no longer in use:
void unregister_chrdev_region(dev_t first, unsigned int count);
Dynamic Allocation of Major Numbers
Some major device numbers are statically assigned to the most common devices. (Documentation/devices.txt)Once the number has been assigned, you can read it from /proc/devices.
To load a driver using a dynamic major number, after calling insmod, you can reads /proc/devices then create the device file(s) for the loaded driver:
module="scull"
major=$(awk "\\$2==\"$module\" {print \\$1}" /proc/devices)
mknod /dev/${device}0 c $major 0
mknod /dev/${device}1 c $major 1
mknod /dev/${device}2 c $major 2
mknod /dev/${device}3 c $major 3
The nodes must be created by the superuser, so newly created special files are owned by root. The access rights must be changed so that non root user can access the device. Tthis example is to give access to a group of users: "staff" or "wheel".
# give appropriate group/permissions, and change the group.
# Not all distributions have staff, some have "wheel" instead.
group="staff"
mode="664"
grep -q '^staff:' /etc/group || group="wheel"
chgrp $group /dev/${device}[0-3]
chmod $mode /dev/${device}[0-3]
You could write an init script which accepts the conventional arguments — start, stop, and restart — and performs the loading and unloading of the driver tasks. The best way to assign major numbers is to use dynamic allocation while leaving yourself the option of specifying the major number at load time, or even at compile time. The scull implementation works in this way: - It uses a global variable, scull_major, to hold the chosen number (there is also a scull_minor for the minor number).
- The variable is initialized to SCULL_MAJOR, defined in scull.h. The default value of SCULL_MAJOR in the distributed source is 0, which means “use dynamic assignment.”
- The user can accept the default or choose a particular major number Either by modifying the macro before compiling or by specifying a value for scull_major on the insmod command line.
if (scull_major) {
dev = MKDEV(scull_major, scull_minor);
result = register_chrdev_region(dev, scull_nr_devs, "scull");
} else {
result = alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull");
scull_major = MAJOR(dev);
}
if (result < 0) {
printk(KERN_WARNING "scull: can't get major %d\n", scull_major);
return result;
}
Some Important Data Structures
File Operations
The structure, file_operations, defined in <linux/fs.h>, is a collection of function pointers.Each open file is represented internally by a file structure and is associated with its own set of functions(by including a field called f_op that points to a file_operations structure). Each field in the file_operations structure must point to the function in the driver that implements a specific operation, or be left NULL for unsupported operations. As you read through the list of methods in file_operations, you will note that a number of parameters include the string __user. This means that a pointer is a user-space address that cannot be directly dereferenced. (it needs to be translated before using in the kernel code)
struct file_operations {
- struct module *owner; This is a pointer to the kernel module that “owns” the structure.
- loff_t (*llseek) (struct file *, loff_t, int); This is used to change the current read/write position in a file, and the new position is returned as a (positive) return value.
- ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); Used to retrieve data from the device. A nonnegative return value represents the number of bytes successfully read.
- ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); Sends data to the device. The return value, if nonnegative, represents the number of bytes successfully written.
- unsigned int (*poll) (struct file *, struct poll_table_struct *); The poll method is the back end of three system calls: poll, epoll, and select. The poll method should return a bit mask indicating whether non- blocking reads or writes are possible and, possibly, provide the kernel with information that can be used to put the calling process to sleep until I/O becomes possible. If a driver leaves its poll method NULL, the device is assumed to be both readable and writable without blocking.
- long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
- long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
- int (*mmap) (struct file *, struct vm_area_struct *); mmap is used to request a mapping of device memory to a process’s address space.
- int (*open) (struct inode *, struct file *); If this entry is NULL, opening the device always succeeds, but your driver isn’t notified.
- int (*flush) (struct file *, fl_owner_t id); The flush operation is invoked when a process closes its copy of a file descriptor for a device
- int (*release) (struct inode *, struct file *); This operation is invoked when the file structure is being released.
- int (*fsync) (struct file *, loff_t, loff_t, int datasync); This method is the back end of the fsync system call, which a user calls to flush any pending data.
- int (*fasync) (int, struct file *, int); This operation is used to notify the device of a change in its FASYNC flag.
- int (*lock) (struct file *, int, struct file_lock *); The lock method is used to implement file locking; it is almost never implemented by device drivers.
- ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
- int (*check_flags)(int); This method allows a module to check the flags passed to an fcntl(F_SETFL...) call.
The file Structure
struct file, defined in <linux/fs.h>, represents an open file. It is created by the kernel on open() and is passed to any function that operates on the file, until the last close(). After all instances of the file are closed, the kernel releases the data structure.struct file {
- ...
- struct path f_path;
struct path path; path = file->f_path; path_get(&path);
The inode Structure
Unix makes a clear distinction between the contents of a file and the information about a file. All information needed by the filesystem to handle a file is included in a data structure called an inode.The inode structure is used by the kernel internally to represent files. There can be numerous file structures representing multiple open descriptors on a single file, but they all point to a single inode structure. In general, only two fields of this inode structure are of interest for writing driver code:
- dev_t i_rdev; For inodes that represent device files, this field contains the actual device number.
- struct cdev *i_cdev; struct cdev is the kernel’s internal structure that represents char devices; this field contains a pointer to that structure when the inode refers to a char device file.
unsigned int iminor(struct inode *inode);
unsigned int imajor(struct inode *inode);
Char Device Registration
The kernel uses structures of type struct cdev (defined in <linux/cdev.h>)to represent char devices internally.struct cdev { struct kobject kobj; struct module *owner; const struct file_operations *ops; struct list_head list; dev_t dev; unsigned int count; };There are two ways of allocating and initializing these structures.
- obtain a standalone cdev structure at runtime
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops = &my_fops;
void cdev_init(struct cdev *cdev, struct file_operations *fops);
Once the cdev structure is set up, the final step is to tell the kernel about it with a call to:
int cdev_add(struct cdev *p, dev_t dev, unsigned count));
p is the cdev structure for the device, dev is the first device number(majot, minor) for which this device is responsible; count is the number of consecutive minor numbers corresponding to this device.
Note that the call to cdev_add() can fail. To remove a char device from the system, call:
void cdev_del(struct cdev *dev);
The big picture,
struct file {
void *private_data;
const struct file_operations *f_op; <-------------------------------+ struct file_operations {
... | int (*open) (struct inode *, struct file *);
+- struct inode *f_inode; | ...
| ... | struct module *owner; --+
| }; | }; |
| | |
| | |
+- struct inode { | |
dev_t i_rdev; | |
struct cdev *i_cdev; <----------+ | |
... | | |
}; | | |
| | |
+ struct cdev { | |
struct kobject kobj; | |
const struct file_operations *ops; --+ |
struct module *owner; --+ struct module {
struct list_head list; ...
dev_t dev; };
...
};
Device Registration in scull
scull represents each device with a structure of type struct scull_dev:
struct scull_dev {
struct scull_qset *data; /* Pointer to first quantum set */
int quantum;
int qset;
unsigned long size;
unsigned int access_key; /* used by sculluid and scullpriv */
struct semaphore sem; /* mutual exclusion semaphore */
struct cdev cdev; /* Char device structure */
};
The struct cdev interfaces our device to the kernel.The structure struct cdev must be initialized and added to the system when the module is initially loaded.
static void scull_setup_cdev(struct scull_dev *dev, int index)
{
int err, devno = MKDEV(scull_major, scull_minor + index);
cdev_init(&dev->cdev, &scull_fops);
dev->cdev.owner = THIS_MODULE;
dev->cdev.ops = &scull_fops;
err = cdev_add(&dev->cdev, devno, 1);
/* Fail gracefully if need be */
if (err)
printk(KERN_NOTICE "Error %d adding scull%d", err, index);
}
The old driver(2.6) does not use the cdev interface, the classic way to register/unregister a char device driver :
int register_chrdev(unsigned int major, const char *name,
struct file_operations *fops);
int unregister_chrdev(unsigned int major, const char *name);
open and release
The open Method
The open method is provided for a driver to do any initialization in preparation for later operations:- Check for device-specific errors (such as device-not-ready or similar hardware problems)
- Initialize the device if it is being opened for the first time
- Update the f_op pointer, if necessary
- Allocate and fill any data structure to be put in filp->private_data
int scull_open(struct inode *inode, struct file *filp)
{
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev; /* for other methods */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) {
scull_trim(dev); /* ignore errors */
}
return 0; /* success */
}
The inode structure contains the struct cdev *i_cdev; field, which is the cdev structure we set up when the module is initially loaded. If cdev is known, we can get the device specific structure via cdev. Therefore, we can set the private_data structure to be the device specific structure via cdev. The container_of macro, defined in <linux/kernel.h>. This macro will expand(return) to a new address pointing to the container which accommodates the respective member: container_of(ptr, type, member)where:
- ptr the pointer to the member.
- type the type of the container struct this is embedded in.
- member the name of the member within the struct.
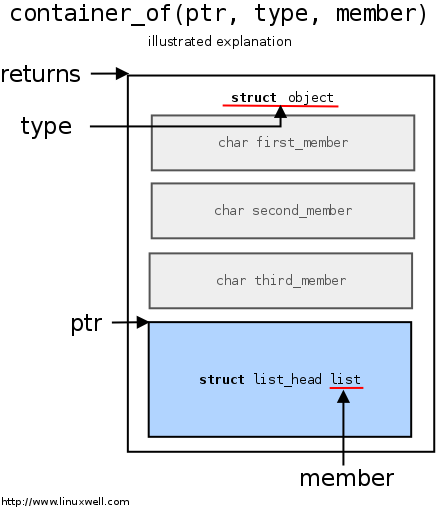
The only real operation performed on the scull device is truncating it to a length of 0 when the device is opened for writing. The operation does nothing if the device is opened for reading.
The release Method
This release method should perform the following tasks:- Deallocate anything that open() allocated in filp->private_data
- Shut down the device on last close. The basic form of scull has no hardware to shut down
int scull_release(struct inode *inode, struct file *filp)
{
return 0;
}
The kernel keeps a counter of how many times a file structure is being used. The close system call executes the release method only when the counter for the file structure drops to 0, which happens when the structure is destroyed. This relationship between the release method and the close system call guarantees that your driver sees only one release call for each open.
read and write
The read and write methods are used to copy data from and to application code.ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp); ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);where
- filp the file pointer
- count the size of the requested data transfer.
- buff argument points to the user buffer holding the data to be written or the empty buffer where the newly read data should be placed.
- offp a pointer to a “long offset type” object that indicates the file position the user is accessing.
unsigned long copy_to_user(void __user *to, const void *from, unsigned long count); unsigned long copy_from_user(void *to, const void __user *from, unsigned long count);As far as the actual device methods are concerned, the task of the read method is to copy data from the device to user space (using copy_to_user), while the write method must copy data from user space to the device (using copy_from_user). Whatever the amount of data the methods transfer, they should generally update the file position at *offp to represent the current file position after successful completion of the system call. A return value greater than or equal to 0, instead, tells the calling program how many bytes have been successfully transferred.
How a typical read implementation uses its arguments:

readv and writev
readv and writev are “vector” versions of read and write. If your driver does not supply methods to handle the vector operations, readv and writev are implemented with multiple calls to your read and write methods.ssize_t (*readv) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos); ssize_t (*writev) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);The iovec structure, defined in <linux/uio.h>,
struct iovec
{
void __user *iov_base;
__kernel_size_t iov_len;
};
Each iovec describes one chunk of data to be transferred; it starts at iov_base (in user space) and is iov_len bytes long.
scull’s Memory Usage
Linux provides a variety of APIs for memory allocation. You can allocate small chunks using kmalloc() or kmem_cache_alloc() families, large virtually contiguous areas using vmalloc() and its derivatives, or you can directly request pages from the page allocator() with alloc_pages().
There are two functions, defined in <linux/slab.h>, are used:
#include <linux/slab.h>
void *kmalloc(size_t size, int flags);
void kfree(void *ptr);
kmalloc is not the most efficient way to allocate large areas of memory. The aim of this section is to show read and write, not memory management. That’s why the code just uses kmalloc and kfree without resorting to allocation of whole pages, although that approach would be more efficient. Most of the memory allocation APIs use GFP_ flags to express how that memory should be allocated. The GFP acronym stands for “get free pages”
The GFP_ flags control the allocators behavior. They tell:
- what memory zones can be used
- how hard the allocator should try to find free memory
- whether the memory can be accessed by the userspace
- GFP_KERNEL Most of the time GFP_KERNEL is what you need. Allocate normal kernel ram. May sleep.
- GFP_NOWAIT If the allocation is performed from an atomic context, e.g interrupt handler. Allocation will not sleep.
- GFP_ATOMIC Allocation will not sleep. May use emergency pools.
- GFP_HIGHUSER Allocate memory from high memory on behalf of user.
- the following additional flags can be OR'ed with the above flags
- __GFP_HIGH This allocation has high priority and may use emergency pools.
- __GFP_NOFAIL Indicate that this allocation is in no way allowed to fail(think twice before using).
- __GFP_NORETRY If memory is not immediately available, then give up at once.
- __GFP_NOWARN If allocation fails, don't issue any warnings.
- __GFP_RETRY_MAYFAIL Try really hard to succeed the allocation but fail eventually.
Playing with the New Devices
You can try using cp, dd, and input/output redirection to test out the driver.
use the strace utility to monitor the system calls issued by a program, together with their return values. Tracing a cp or an ls -l > /dev/scull0 shows quantized reads and writes.
- build make
- load scull_load will do the following:
- load the scull.ko module.
- create device nodes
lrwxrwxrwx 1 root root 6 十二 4 11:10 /dev/scull -> scull0 crw-rw-r-- 1 root staff 238, 0 十二 4 11:10 /dev/scull0 crw-rw-r-- 1 root staff 238, 1 十二 4 11:10 /dev/scull1 crw-rw-r-- 1 root staff 238, 2 十二 4 11:10 /dev/scull2 crw-rw-r-- 1 root staff 238, 3 十二 4 11:10 /dev/scull3 lrwxrwxrwx 1 root root 10 十二 4 11:10 /dev/scullpipe -> scullpipe0 crw-rw-r-- 1 root staff 238, 4 十二 4 11:10 /dev/scullpipe0 crw-rw-r-- 1 root staff 238, 5 十二 4 11:10 /dev/scullpipe1 crw-rw-r-- 1 root staff 238, 6 十二 4 11:10 /dev/scullpipe2 crw-rw-r-- 1 root staff 238, 7 十二 4 11:10 /dev/scullpipe3 crw-rw-r-- 1 root staff 238, 11 十二 4 11:10 /dev/scullpriv crw-rw-r-- 1 root staff 238, 8 十二 4 11:10 /dev/scullsingle crw-rw-r-- 1 root staff 238, 9 十二 4 11:10 /dev/sculluid crw-rw-r-- 1 root staff 238, 10 十二 4 11:10 /dev/scullwuidOr, use the script scull.init. This provides start, stop and restart actions. You need to provide a configuration file /etc/scull.conf:
owner jerry group jerry mode ug+rw
- lsmod | grep scull
scull 20480 0
$ echo "test" > /dev/scull $ cat /dev/scull test
scull's Source
Makefile
- ccflags-y specifies options for compiling with $(CC). Example:
# drivers/acpi/acpica/Makefile ccflags-y := -Os -D_LINUX -DBUILDING_ACPICA ccflags-$(CONFIG_ACPI_DEBUG) += -DACPI_DEBUG_OUTPUTThis variable is necessary because the top Makefile owns the variable $(KBUILD_CFLAGS) and uses it for compilation flags for the entire tree. Flags with the same behaviour were previously named: EXTRA_CFLAGS
scull.h
- Debug control
- Split minors in two parts
- Define driver's ioctl number include/uapi/asm-generic/ioctl.h:
#ifdef SCULL_DEBUG
# ifdef __KERNEL__
/* Debugging is on and we are in kernelspace. */
# define PDEBUG(fmt, args...) printk(KERN_DEBUG "scull: " fmt, ## args)
# else
/* Debugging is on and we are in userspace. */
# define PDEBUG(fmt, args...) fprintf(stderr, fmt, ## args)
# endif
#else
# define PDEBUG(fmt, args...) /* Not debugging: do nothing. */
#endif
struct scull_qset {
void **data;
struct scull_qset *next;
};
#define TYPE(minor) (((minor) >> 4) & 0xf) /* high nibble */
#define NUM(minor) ((minor) & 0xf) /* low nibble */
#define _IOC_TYPEBITS 8
#define _IOC_SIZEBITS 14
#define _IOC_DIRBITS 2
#define _IOC_NRBITS 8
#define _IOC(dir,type,nr,size) \
(((dir) << _IOC_DIRSHIFT) | \
((type) << _IOC_TYPESHIFT) | \
((nr) << _IOC_NRSHIFT) | \
((size) << _IOC_SIZESHIFT))
#define _IOC_TYPECHECK(t) (sizeof(t))
/*
* Used to create numbers.
*
* NOTE: _IOW means userland is writing and kernel is reading.
* _IOR means userland is reading and kernel is writing.
*/
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define SCULL_IOC_MAGIC 'k'
#define SCULL_IOCRESET _IO(SCULL_IOC_MAGIC, 0)
#define SCULL_IOCSQUANTUM _IOW(SCULL_IOC_MAGIC, 1, int)
#define SCULL_IOCSQSET _IOW(SCULL_IOC_MAGIC, 2, int)
#define SCULL_IOCTQUANTUM _IO(SCULL_IOC_MAGIC, 3)
#define SCULL_IOCTQSET _IO(SCULL_IOC_MAGIC, 4)
#define SCULL_IOCGQUANTUM _IOR(SCULL_IOC_MAGIC, 5, int)
#define SCULL_IOCGQSET _IOR(SCULL_IOC_MAGIC, 6, int)
#define SCULL_IOCQQUANTUM _IO(SCULL_IOC_MAGIC, 7)
#define SCULL_IOCQQSET _IO(SCULL_IOC_MAGIC, 8)
#define SCULL_IOCXQUANTUM _IOWR(SCULL_IOC_MAGIC, 9, int)
#define SCULL_IOCXQSET _IOWR(SCULL_IOC_MAGIC,10, int)
#define SCULL_IOCHQUANTUM _IO(SCULL_IOC_MAGIC, 11)
#define SCULL_IOCHQSET _IO(SCULL_IOC_MAGIC, 12)
#define SCULL_P_IOCTSIZE _IO(SCULL_IOC_MAGIC, 13)
#define SCULL_P_IOCQSIZE _IO(SCULL_IOC_MAGIC, 14)
 In scull, each device has a scull_dev structure which contains a data area composed of a linked list of scull_qset . Each scull_qset is equipped with a set of memory area. We call each memory area a quantum and the array (or its length) a quantum set. A new quantum will be allocated when the scull_write() is called. scull_trim() simply walks through the list and frees any quantum and quantum set it finds.
In scull, each device has a scull_dev structure which contains a data area composed of a linked list of scull_qset . Each scull_qset is equipped with a set of memory area. We call each memory area a quantum and the array (or its length) a quantum set. A new quantum will be allocated when the scull_write() is called. scull_trim() simply walks through the list and frees any quantum and quantum set it finds. main.c
...
int scull_major = SCULL_MAJOR;
...
module_param(scull_major, int, S_IRUGO);
...
struct scull_dev *scull_devices; /* allocated in scull_init_module */
...
int scull_trim(struct scull_dev *dev)
{
struct scull_qset *next, *dptr;
int qset = dev->qset; /* "dev" is not-null */
int i;
for (dptr = dev->data; dptr; dptr = next) { /* all the list items */
if (dptr->data) {
for (i = 0; i < qset; i++)
kfree(dptr->data[i]);
kfree(dptr->data);
dptr->data = NULL;
}
next = dptr->next;
kfree(dptr);
}
dev->size = 0;
dev->quantum = scull_quantum;
dev->qset = scull_qset;
dev->data = NULL;
return 0;
}
...
int scull_init_module(void)
{
...
/*
* Get a range of minor numbers to work with, asking for a dynamic
* major unless directed otherwise at load time.
*/
if (scull_major) {
dev = MKDEV(scull_major, scull_minor);
result = register_chrdev_region(dev, scull_nr_devs, "scull");
} else {
result = alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull");
scull_major = MAJOR(dev);
}
if (result < 0) {
printk(KERN_WARNING "scull: can't get major %d\n", scull_major);
return result;
}
...
scull_devices = kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL);
...
/* Initialize each scull's device instance. */
for (i = 0; i < scull_nr_devs; i++) {
scull_devices[i].quantum = scull_quantum;
scull_devices[i].qset = scull_qset;
sema_init(&scull_devices[i].sem, 1);
scull_setup_cdev(&scull_devices[i], i);
}
/* At this point call the init function for any friend device: scull_p and scull_a */
dev = MKDEV(scull_major, scull_minor + scull_nr_devs);
dev += scull_p_init(dev);
dev += scull_access_init(dev);
#ifdef SCULL_DEBUG /* only when debugging */
scull_create_proc();
#endif
return 0; /* succeed */
fail:
scull_cleanup_module();
return result;
}
module_init(scull_init_module);
module_exit(scull_cleanup_module);
pipe.c
int scull_p_init(dev_t firstdev)
{
int i, result;
result = register_chrdev_region(firstdev, scull_p_nr_devs, "scullp");
if (result < 0) {
printk(KERN_NOTICE "Unable to get scullp region, error %d\n", result);
return 0;
}
scull_p_devno = firstdev;
scull_p_devices = kmalloc(scull_p_nr_devs * sizeof(struct scull_pipe), GFP_KERNEL);
if (scull_p_devices == NULL) {
unregister_chrdev_region(firstdev, scull_p_nr_devs);
return 0;
}
memset(scull_p_devices, 0, scull_p_nr_devs * sizeof(struct scull_pipe));
for (i = 0; i < scull_p_nr_devs; i++) {
init_waitqueue_head(&(scull_p_devices[i].inq));
init_waitqueue_head(&(scull_p_devices[i].outq));
sema_init(&scull_p_devices[i].sem, 1);
scull_p_setup_cdev(scull_p_devices + i, i);
}
#ifdef SCULL_DEBUG
proc_create("scullpipe", 0, NULL, &scullpipe_proc_ops);
#endif
return scull_p_nr_devs;
}
access.c
static void scull_access_setup (dev_t devno, struct scull_adev_info *devinfo)
{
struct scull_dev *dev = devinfo->sculldev;
int err;
/* Initialize the device structure */
dev->quantum = scull_quantum;
dev->qset = scull_qset;
sema_init(&dev->sem, 1);
/* Do the cdev stuff. */
cdev_init(&dev->cdev, devinfo->fops);
kobject_set_name(&dev->cdev.kobj, devinfo->name);
dev->cdev.owner = THIS_MODULE;
err = cdev_add (&dev->cdev, devno, 1);
/* Fail gracefully if need be */
if (err) {
printk(KERN_NOTICE "Error %d adding %s\n", err, devinfo->name);
kobject_put(&dev->cdev.kobj);
} else
printk(KERN_NOTICE "%s registered at %x\n", devinfo->name, devno);
}
int scull_access_init(dev_t firstdev)
{
int result, i;
/* Get our number space */
result = register_chrdev_region (firstdev, SCULL_N_ADEVS, "sculla");
if (result < 0) {
printk(KERN_WARNING "sculla: device number registration failed\n");
return 0;
}
scull_a_firstdev = firstdev;
/* Set up each device. */
for (i = 0; i < SCULL_N_ADEVS; i++)
scull_access_setup (firstdev + i, scull_access_devs + i);
return SCULL_N_ADEVS;
}
Playing with the scull Devices
The device acts like a data buffer whose length is limited only by the amount of real RAM available.- You can try using cp, dd, and input/output redirection
- The free command can be used to see how the amount of free memory shrinks and expands according to how much data is written into scull.
- Use the strace utility to monitor the system calls issued by a program, together with their return values.
Build errors
access.c:31:10: fatal error: linux/malloc.h: No such file or directory
#include <linux/malloc.h> /* kmalloc() */
^~~~~~~~~~~~~~~~
compilation terminated.
kmalloc() is defined in linux/slab.h.
main.c:24:10: fatal error: linux/config.h: No such file or directory #include <linux/config.h>linux/config.h is deprecated from 2.6.19. Simply sed or patch out any references to linux/config.h with linux/generated/autoconf.h
/lib/modules/5.0.0-36-generic/build/include/linux/compiler.h:250:10: fatal error: asm/barrier.h: No such file or directory
#include <asm/barrier.h>
^~~~~~~~~~~~~~~
The header file architecture is changed to be : #include <asm-generic/barrier.h> sudo ln -s asm-generic asm
error: implicit declaration of function ‘copy_to_user’; did you mean ‘raw_copy_to_user’? [-Werror=implicit-function-declaration]#include <linux/uaccess.h>
error: macro "access_ok" passed 3 arguments, but takes just 2 err = !access_ok(VERIFY_WRITE,(void __user *)arg, _IOC_SIZE(cmd));
error: implicit declaration of function ‘signal_pending’#include <linux/sched/signal.h>
error: invalid operands to binary != (have ‘uid_t {aka unsigned int}’ and ‘kuid_t {aka const struct }’)
(scull_u_owner != current->cred->uid->uid) && /* allow user */
typedef struct {
uid_t val;
} kuid_t;
struct cred {
...
kuid_t uid; /* real UID of the task */
...
} __randomize_layout;
static uid_t scull_u_owner;
Do the following change:
static kuid_t scull_u_owner;
if (scull_u_count &&
( !uid_eq(scull_u_owner , current_uid()) )&& /* allow user */
( !uid_eq(scull_u_owner , current_euid()) ) && /* allow whoever did su */
!capable(CAP_DAC_OVERRIDE)) { /* still allow root */
spin_unlock(&scull_u_lock);
return -EBUSY; /* -EPERM would confuse the user */
}
if (scull_u_count == 0)
scull_u_owner = current_uid(); /* grab it */
static kuid_t scull_w_owner; /* initialized to 0 by default */
uid_eq(scull_u_owner , current_uid()) ||
uid_eq(scull_u_owner , current_euid()) ||
error: dereferencing pointer to incomplete type ‘struct signal_struct’
if (!current->signal->tty) {
^~
This is because of the struct whose definition is not found. Add the following :
include/linux/sched/signal.h
留言