Git Branching
Git Branching
Branching means you diverge from the main line of development and continue to do work without messing with that main line. The way Git branches is incredibly lightweight, making branching operations nearly instantaneous and switching back and forth between branches generally just as fast.
Git stores data as a series of snapshots.
When you commit in Git, Git stores a commit object that contains a pointer to the snapshot of the content you staged. .
The Git Object Model
All the information needed to represent the history of a project is stored in files referenced by 40-character strings which is calculated by taking the SHA1 hash of the contents of the object.Every object consists of three things - a type, a size and content.
The size is simply the size of the contents, the contents depend on what type of object it is, and there are four different types of objects: "blob", "tree", "commit", and "tag".
- A "blob" is used to store file data - it is generally a file.
- A "tree" is basically like a directory - it references a bunch of other trees and/or blobs (i.e. files and sub-directories)
- A "commit" points to a single tree, marking it as what the project looked like at a certain point in time. It contains meta-information about that point in time, such as a timestamp, the author of the changes since the last commit, a pointer to the previous commit(s), etc. , and pointers to the commit or commits that directly came before this commit (its parent or parents):
- zero parents for the initial commit
- one parent for a normal commit
- multiple parents for a commit that results from a merge of two or more branches
- A "tag" is a way to mark a specific commit as special in some way. It is normally used to tag certain commits as specific releases or something along those lines.
Branches in a Nutshell
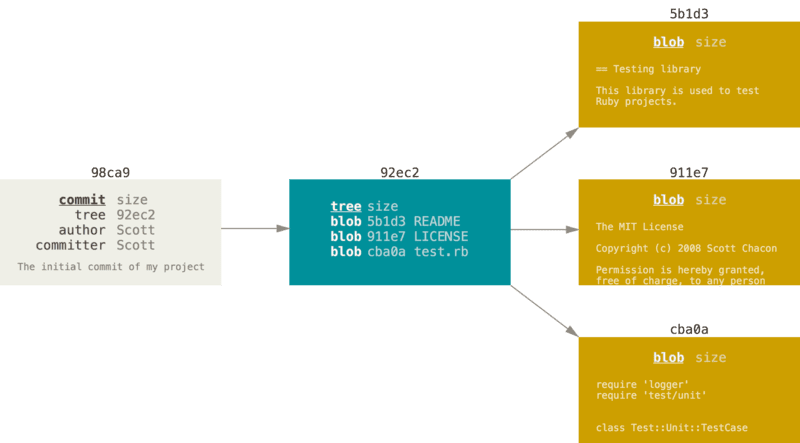
To really understand the way Git does branching, we need to take a step back and examine how Git stores its data.To visualize this, let’s assume that you have a directory containing three files, and you stage them all and commit.
Staging the files computes a checksum(SHA1) for each one, stores that version of the file in the Git repository (blobs), and adds that checksum to the staging area:
$ touch README test.rb LICENSE $ git add README test.rb LICENSE $ git commit -m 'Add 3 files'Your Git repository now contains five objects:
- three blobs (each representing the contents of one of the three files)
- one tree that lists the contents of the directory and specifies which file names are stored as which blobs
- one commit with the pointer to that root tree and all the commit metadata

git init command creates the master branch by default Every time you commit, the master branch pointer moves forward automatically.
Creating a New Branch
Creating a new branch just creates a new pointer to the same commit you’re currently on.Let’s say you want to create a new branch called testing.
$ git branch testing $ git branch * master testing

The git branch command only created a new branch — it didn’t switch to that branch.

$ git log --oneline --decorate 5d0b90e (HEAD -> master, testing) Add 3 files bcbcc1b (origin/master) 1st file for testing
Switching Branches
To switch to an existing branch, you run the git checkout command.$ git checkout testing Switched to branch 'testing'This moves HEAD to point to the testing branch.

$ echo "haha" > test.rb $ git commit -a -m 'made a change'The HEAD branch moves forward when a commit is made,

Let’s switch back to the master branch:

Remote Branches
Remote references include branches, tags, and so on.Remote references are pointers in your remote repositories.
- To get a full list of remote references
$ git ls-remote origin
9aaf78c161cef49da351c1cc30a4269720f85dd2 HEAD
07da1593883bc89e05d9956c5a69a716f0e67459 refs/heads/argos
61902304815412a297716329632de98464b78c80 refs/heads/arm64-ebbr
70f9df156f0f8a84592bad7178a054a6ee61dbed refs/heads/build-bot-without-mouting-somervilleshare
9aaf78c161cef49da351c1cc30a4269720f85dd2 refs/heads/master
5863c66c0af72b5284d57b76fbbc21292871523b refs/heads/sutton
1d71f82a6900babc54b391db9df719a68c93b675 refs/heads/sutton-lb3x
$ git remote show origin
* remote origin
Fetch URL: git+ssh://jerry-lee-tpe@git.launchpad.net/~jerry-lee-tpe/lyoncore/+git/image-build
Push URL: git+ssh://jerry-lee-tpe@git.launchpad.net/~jerry-lee-tpe/lyoncore/+git/image-build
HEAD branch: master
Remote branches:
argos new (next fetch will store in remotes/origin)
arm64-ebbr new (next fetch will store in remotes/origin)
build-bot-without-mouting-somervilleshare new (next fetch will store in remotes/origin)
master new (next fetch will store in remotes/origin)
sutton new (next fetch will store in remotes/origin)
sutton-lb3x new (next fetch will store in remotes/origin)
Local ref configured for 'git push':
master pushes to master (local out of date)
Remote-tracking branches are references to the state of remote branches. Remote-tracking branches are local references that you can’t move; Git moves them for you automatically.
Remote-tracking branch names take the form <remote>/<branch>.
For instance, if you wanted to see what the master branch on your origin remote looked like as of the last time you communicated with it, you would check the origin/master branch.
“origin” is the default name for a remote when you run git clone.
If you clone from this, Git’s clone command automatically names it origin for you, pulls down all its data, creates a pointer to where its master branch is, and names it origin/master locally.
If you clone from a remote git server, Git’s clone command:
- automatically names it origin for you, pulls down all its data, creates a pointer to where its master branch is, and names it origin/master locally.
- gives you your own local master branch starting at the same place as origin’s master branch, so you have something to work from.

If you do some work on your local master branch, and, in the meantime, someone else pushes to git.ourcompany.com and updates its master branch, then your histories move forward differently.
To solve this problem, to synchronize your work with a given remote, you run a git fetch <remote> command (in our case, git fetch origin).
Assume :
- The primary Git server is at git.ourcompany.com
- The development Git server is at git.team1.ourcompany.com

Now, you can run git fetch teamone to fetch everything the remote teamone server has that you don’t have yet. A remote-tracking branch called teamone/master is set to point to the commit that teamone has as its master branch.


留言